新・基本情報 科目 B アルゴリズムとプログラミング サンプル問題 解説 2
2022-07-21 更新

2023 年 4 月から基本情報技術者試験の制度が変更され、特に科目 B 試験(従来の午後試験に該当するもの)の内容が大きく変わります。 IPA(独立行政法人情報処理推進機構)は、「基本情報技術者試験 科目 B のサンプル問題」として、アルゴリズムとプログラミングの問題を 5 問と、情報セキュリティの問題を 1 問だけ公開しています。
前回の記事では、アルゴリズムとプログラミングの問題を 3 問取り上げました。 この記事では、残りの 2 問を取り上げて、解法のポイントを説明します。
サンプル問題(問 4 ) データを特性に応じた構造に変換する
アルゴリズムとプログラミングの問題は、
- 「プログラムの基本要素(型、変数、配列、代入、算術演算、比較演算、論理演算、選択処理、繰返し処理、手続・関数の呼出し、など)」
- 「データ構造及びアルゴリズム(再帰、スタック、キュー、木構造、グラフ、連結リスト、整列、文字列処理、など)」
- 「プログラミングの諸分野への適用(数理・データサイエンス・ AI などの分野を題材としたプログラム、など)」
という 3 つのカテゴリに分けられています。
サンプル問題の問 4 は「プログラミングの諸分野への適用」の問題です。 出題趣旨は、
「多変量解析や機械学習などを用いたデータサイエンスの取組に当たっては、データを、特性に応じた構造に変換することがある。本問では、疎行列の格納に適したデータ構造への変換を題材として、プログラムの動作の理解を問う」
です。 以下に、問題を示します。
問 4
次の記述中のa~cに入れる正しい答えの組合せを,解答群の中から選べ。ここで,配列の要素番号は 1 から始まる。
要素の多くが 0 の行列を疎行列という。次のプログラムは,二次元配列に格納された行列のデータ量を削減するために,疎行列の格納に適したデータ構造に変換する。
関数 transformSparseMatrix は,引数 matrix で二次元配列として与えられた行列を,整数型配列の配列に変換して返す。 関数 transformSparseMatrix を
transformSparseMatrix({{3, 0, 0, 0, 0}, {0, 2, 2, 0, 0}, {0, 0, 0, 1, 3}, {0, 0, 0, 2, 0}, {0, 0, 0, 0, 1}}) として呼び出したときの戻り値は,{{ a }, { b }, { c }} である。
〔プログラム〕
○整数型配列の配列: transformSparseMatrix(整数型の二次元配列: matrix)
整数型: i, j
整数型配列の配列: sparseMatrix
sparseMatrix ← {{}, {}, {}} /* 要素数0の配列を三つ要素にもつ配列 */
for (i を 1 から matrixの行数 まで 1 ずつ増やす)
for (j を 1 から matrixの列数 まで 1 ずつ増やす)
if (matrix[i, j] が 0 でない)
sparseMatrix[1]の末尾 に iの値 を追加する
sparseMatrix[2]の末尾 に jの値 を追加する
sparseMatrix[3]の末尾 に matrix[i, j]の値 を追加する
endif
endfor
endfor
return sparseMatrix
解答群
| a | b | c | |
|---|---|---|---|
| ア | 1, 2, 2, 3, 3, 4, 5 | 1, 2, 3, 4, 5, 4, 5 | 3, 2, 2, 1, 2, 3, 1 |
| イ | 1, 2, 2, 3, 3, 4, 5 | 1, 2, 3, 4, 5, 4, 5 | 3, 2, 2, 1, 3, 2, 1 |
| ウ | 1, 2, 3, 4, 5, 4, 5 | 1, 2, 2, 3, 3, 4, 5 | 3, 2, 2, 1, 2, 3, 1 |
| エ | 1, 2, 3, 4, 5, 4, 5 | 1, 2, 2, 3, 3, 4, 5 | 3, 2, 2, 1, 3, 2, 1 |
出題趣旨に沿って、問題の内容を見てみましょう。
「変量解析や機械学習などを用いたデータサイエンスの取組み」
という大きな趣旨ではあっても、そのほんの一部である
「データを、特性に応じた構造に変換すること」
がテーマの問題です。
「二次元配列に格納された行列のデータ量を削減するために、疎行列の格納に適したデータ構造に変換する」
ためのプログラムが示されているので、その内容から変換方法を読み取ってください。
- 「行列」
- 要素を縦と横に並べたものであり、プログラムでは 2 次元配列で表せます。
- 「疎行列」
- ほとんどの要素が 0 である行列のことです。 0 でない要素だけを保存すれば、疎行列のデータ量を削減できます。
多くのプログラミング言語では、 2 次元配列を「 1 次元配列を要素とした 1 次元配列」として表現します。 この問題に示されたプログラムも同様です。 変換する前の疎行列は、以下の内容になっています。 ここでは、わかりやすいように、要素( 2 次元配列の要素の 1 次元配列)ごとに改行して示しています。
matrix = {
{3, 0, 0, 0, 0}, label 1 行目
{0, 2, 2, 0, 0}, label 2 行目
{0, 0, 0, 1, 3}, label 3 行目
{0, 0, 0, 2, 0}, label 4 行目
{0, 0, 0, 0, 1}, label 5 行目
}
こうすると、行と列がわかりやすくなります。 問題文の中に
「配列の要素番号は 1 から始まる」
とあるので、先頭は 0 行目ではなく 1 行目です。
ここでは、変換前の 2 次元配列が matrix であり、変換後の 2 次元配列が sparseMatrix です。
for 文による多重ループで matrix[i行][j列] を取り出し、もしも値が 0 でないなら、 sparseMatrix[1] の末尾に i の値を追加し、 sparseMatrix[2] の末尾に j の値を追加し、 sparseMatrix[3] の末尾に matrix[i行][j列] の値を追加します。
つまり、疎行列の 0 でない要素を取り出し、その行の値を sparseMatrix[1] に、列の値を sparseMatrix[2] に、要素の値を sparseMatrix[3] に格納するのです。 これは、プログラムの以下の部分です。
for (i を 1 から matrixの行数 まで 1 ずつ増やす)
for (j を 1 から matrixの列数 まで 1 ずつ増やす)
if (matrix[i, j] が 0 でない)
sparseMatrix[1]の末尾 に iの値 を追加する label 要素の行の値
sparseMatrix[2]の末尾 に jの値 を追加する label 要素の列の値
sparseMatrix[3]の末尾 に matrix[i, j]の値 を追加する label 要素の値
endif
endfor
endfor
ここまでプログラムを読み取れれば、変換後の sparseMatrix の内容がわかるでしょう。
以下に示したように、変換前の疎行列 matrix の (1) ~ (7) の要素の行、列、値が、それぞれ sparseMatrix[1] 、 sparseMatrix[2] 、 sparseMatrix[3] に追加されていきます。
matrix = {
{3(1), 0, 0, 0, 0}, (1) 1 行、 1 列、値 3
{0, 2(2), 2(3), 0, 0}, (2) 2 行、 2 列、値 2 / (3) 2 行、 3 列、値 2
{0, 0, 0, 1(4), 3(5)}, (4) 3 行、 4 列、値 1 / (5) 3 行、 5 列、値 3
{0, 0, 0, 2(6), 0}, (6) 4 行、 4 列、値 2
{0, 0, 0, 0, 1(7)}, (7) 5 行、 5 列、値 1
}
したがって、
sparseMatrix[1] の内容は {1, 2, 2, 3, 3, 4, 5}、
sparseMatrix[2] の内容は {1, 2, 3, 4, 5, 4, 5}、
sparseMatrix[3] の内容は {3, 2, 2, 1, 3, 2, 1}
になります。選択肢イが正解です。
サンプル問題(問 5 )ライブラリを適切に利用する
サンプル問題の問 5 も「プログラミングの諸分野への適用」の問題です。出題趣旨は、
「文書を構成する言葉や文字に関する統計情報は、自然言語処理などに活用されている。本問では、ある文字に後続する文字の出現割合の計算を題材として、問題文に示されたプログラムの仕様を理解した上で、ライブラリを適切に利用し、正しく処理を実装する能力を問う」
です。以下に、問題を示します。
問 5
次のプログラム中のaとbに入れる正しい答えを,解答群の中から選べ。
任意の異なる 2 文字を c1, c2 とするとき,英単語群に含まれる英単語において, c1 の次に c2 が出現する割合を求めるプログラムである。英単語は,英小文字だけから成る。英単語の末尾の文字が c1 である場合,その箇所は割合の計算に含めない。例えば,図に示す 4 語の英単語 “importance” , “inflation” , “information” , “innovation” から成る英単語群において, c1 を “n” , c2 を “f” とする。英単語の末尾の文字以外に “n” は五つあり,そのうち次の文字が “f” であるものは二つである。したがって,求める割合は, 2 ÷ 5 = 0.4 である。 c1 と c2 の並びが一度も出現しない場合, c1 の出現回数によらず割合を 0 と定義する。
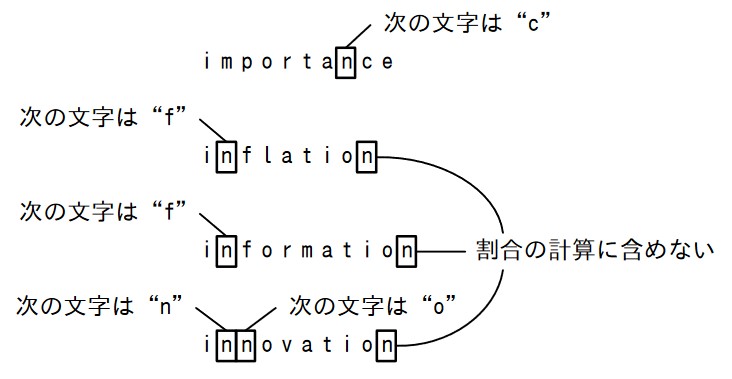
プログラムにおいて,英単語群は Words 型の大域変数 words に格納されている。クラス Words のメソッドの説明を,表に示す。本問において,文字列に対する演算子 “+” は,文字列の連結を表す。また,整数に対する演算子 “÷” は,実数として計算する。
| メソッド | 戻り値 | 説明 |
|---|---|---|
| freq(文字列型: str) | 整数型 | 英単語群中の文字列 str の出現回数を返す。 |
| freqE(文字列型: str) | 整数型 | 英単語群の中で,文字列 str で終わる英単語の数を返す。 |
〔プログラム〕
大域: Words: words /* 英単語群が格納されている */ /* c1の次にc2が出現する割合を返す */ ○実数型: prob(文字型: c1, 文字型: c2) 文字列型: s1 ← c1の1文字だけから成る文字列 文字列型: s2 ← c2の1文字だけから成る文字列 if (words.freq(s1 + s2) が 0 より大きい) return else return 0 endif
解答群
- ア
- (words.freq(s1) – words.freqE(s1)) ÷ words.freq(s1 + s2)
- イ
- (words.freq(s2) – words.freqE(s2)) ÷ words.freq(s1 + s2)
- ウ
- words.freq(s1 + s2) ÷ (words.freq(s1) – words.freqE(s1))
- エ
- words.freq(s1 + s2) ÷ (words.freq(s2) – words.freqE(s2))
この問題も
「文書を構成する言葉や文字に関する統計情報は、自然言語処理などに活用されている」
という壮大な趣旨ではあっても、そのほんの一部である
「ある文字に後続する文字の出現割合の計算」
がテーマです。
さらに
「ライブラリを適切に利用し、正しく処理を実装する能力を問う」
という趣旨にも注目してください。
数理、データサイエンス、 AI などのプログラミングでは、あらかじめ用意されているライブラリを活用する場面が多いので、このような趣旨なのでしょう。 どのような機能のライブラリを使うのかは、問題ごとに示されるはずです。
ここでは、ライブラリとして提供されている Word クラスを使います。
問題文を見ると、 Word クラス型の大域変数 word の中に英単語群(複数の英単語)が格納されていて、 Word クラスが freq(文字列型:str) メソッドおよび freqE(文字列型:str) メソッドを持っています。 これらのメソッドの機能を理解することが、問題を解く大きなポイントになります。
問題に示された図から、
「 c1 の次に c2 が出現する割合を求める」
の意味を読み取りましょう。
c1 を “n” 、 c2 を “f” とした場合、 “nf” の出現回数 ÷ ( “n” の出現回数 – 末尾に “n” が出現する回数) を求めればよいことがわかります。
プログラムを見ると、文字 c1 を文字列 s1 に変換し、文字 c2 を文字列 s2 に変換しています。 これは、文字と文字列を区別するプログラミング言語を想定しているのでしょう。問題文に
「文字列に対する演算子 “+” は、文字列の連結を表す」
とあるので、 s1 + s2 は、 “nf” という文字列になります。
問題に示された表に、
- freq(文字列型:str)メソッド
- 「英単語群中の文字列 str の出現回数を返す」
- freqE(文字列型:str)メソッド
- 「英単語群の中で、文字列 str で終わる英単語の数を返す」
という説明があります。
したがって、 “nf” の出現回数 ÷ (“n”の出現回数 – 末尾に “n” が出現する回数) は、
words.freq(s1 + s2) ÷ (words.freq(s1) - words.freqE(s1))
となり、選択肢ウが正解です。
もしも、このサンプル問題と同様の問題が従来の午後試験で出題されたとしたら、配列に格納された文字列をコツコツと処理するプログラムが示されたはずです。 それがライブラリを利用するプログラムになっているのですから、科目 B 試験のアルゴリズムとプログラミングの問題は、従来よりも解きやすくなった(やさしくなった)といえます。
ただし、まったくプログラミング経験がないと、問題の意味がわからないでしょう。
試験対策として、 Java や Python など、ライブラリを活用するプログラミング言語を学習しておくべきです。 科目 B 試験には、プログラミング言語の問題がありませんが、プログラミング言語の知識と経験が要求されます。
問 4 - イ 問 5- ウ
以上、「基本情報技術者試験 科目 B 試験のサンプル問題」の中から、アルゴリズムとプログラミングの問題を取り上げて、解法のポイントを説明しました。 2023 年 4 月以降に基本情報技術者試験を受験される方の参考になれば幸いです。
科目 B のサンプル問題には、情報セキュリティの問題もあります。この問題は、今後の記事で取り上げる予定です。
label 関連タグ免除試験を受けた 74.9% の方が、科目A免除資格を得ています。
※独習ゼミは、受験ナビ運営のSEプラスによる試験対策eラーニングです。

基本情報技術者試験 科目A免除試験の講評 ~ 2026年6月14日実施
update
【2026-2027年度】情報処理技術者試験が大幅刷新!応用情報・高度試験の再編や、基本情報技術者試験への影響まで解説!
update
基本情報技術者試験 科目A免除試験の講評 ~ 2026年1月25日実施
update
基本情報技術者試験 科目A免除試験の講評 ~ 2025年12月14日実施
update
令和7年度 基本情報技術者試験 公開問題の講評
update
基本情報技術者試験 科目A免除試験 (旧 午前免除試験) の講評 ~ 2025年7月27日実施
update
基本情報技術者試験 科目A免除試験 (旧 午前免除試験) の講評 ~ 2025年6月8日実施
update
基本情報技術者試験 科目A免除試験(修了試験)の講評 ~ 2025年1月26日実施
update
基本情報技術者試験 科目A免除試験(修了試験)の講評 ~ 2024年12月8日実施
update
基本情報技術者試験 科目A免除試験(修了試験)の講評 ~ 2024年7月28日実施
update
『プログラムはなぜ動くのか』(日経BP)が大ベストセラー
IT技術を楽しく・分かりやすく教える“自称ソフトウェア芸人”
大手電気メーカーでPCの製造、ソフトハウスでプログラマを経験。独立後、現在はアプリケーションの開発と販売に従事。その傍ら、書籍・雑誌の執筆、またセミナー講師として活躍。軽快な口調で、知識0ベースのITエンジニアや一般書店フェアなどの一般的なPCユーザの講習ではダントツの評価。
お客様の満足を何よりも大切にし、わかりやすい、のせるのが上手い自称ソフトウェア芸人。
主な著作物
- 「プログラムはなぜ動くのか」(日経BP)
- 「コンピュータはなぜ動くのか」(日経BP)
- 「出るとこだけ! 基本情報技術者」 (翔泳社)
- 「ベテランが丁寧に教えてくれる ハードウェアの知識と実務」(翔泳社)
- 「ifとelseの思考術」(ソフトバンククリエイティブ) など多数







