「厳選5題」過去問と解説 | 平成28年度 秋期 の過去問やるならこれをやれ
2020-03-09 更新

ここでは、平成 28 年度 秋期 基本情報技術者試験の午前試験 の中から「やるべき問題」を5題に厳選し、ぶっちゃけた解説をさせていただきます。
やるべき問題とは、よく出る問題であり、かつ、練習すればできる問題(練習しないとできない問題)です。
もくじ
厳選問題looks_oneAND によるビット演算のイメージをつかんでおこう
8 ビットのビット列の下位 4 ビットが変化しない操作はどれか。
- ア
- 16 進表記 0F のビット列との排他的論理和をとる。
- イ
- 16 進表記 0F のビット列との否定論理積をとる。
- ウ
- 16 進表記 0F のビット列との論理積をとる。
- エ
- 16 進表記 0F のビット列との論理和をとる。
この問題は、「ビット演算(マスク演算とも呼ばれる)」がテーマです。 ビット演算 とは、 2 進数のデータを論理演算することです。
説明するより具体例を示した方が早いと思いますので、以下を見てください。
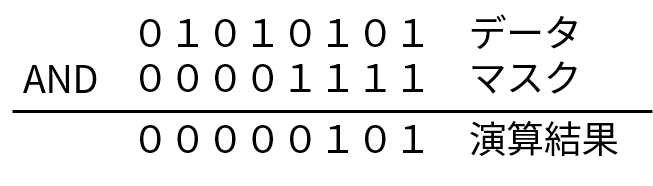
01010101 と 00001111 という 2 進数で AND 演算を行っています。
01010101 には「データ」、 00001111 には「マスク」という名前を付けています。 これらの名前の意味は、あとでわかります。
ビット演算では、 2 進数の 1 桁ずつで論理演算をします。
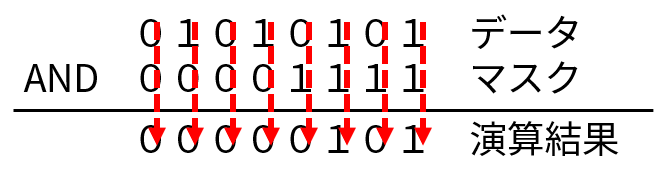
ここでは、 AND 演算ですから、以下の矢印の方向でデータとマスクの 1 桁ずつを AND 演算します。 AND 演算は、演算する 2 つの値が両方とも 1 のときだけ演算結果が 1 になります。 ここまでは、OK でしょうか?
それでは、あらためてデータ、マスク、演算結果を見てみましょう。
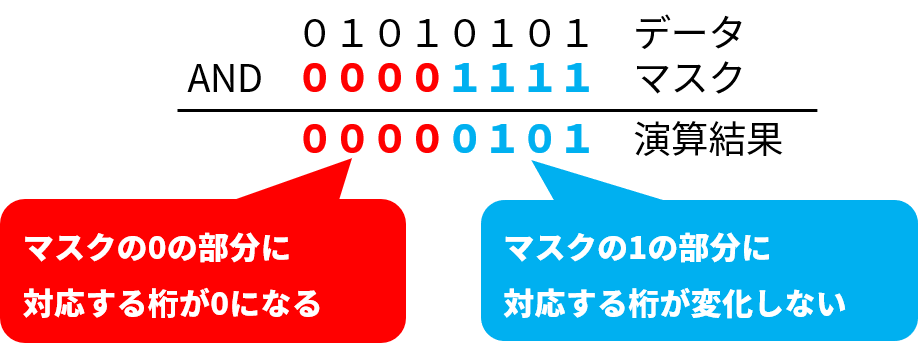
データの 01010101 のうち、マスクの 00001111 の 0 の部分に対応する桁が 0 になり、 1 の部分に対応する桁が変化せずに、 00000101 という演算結果が得られました。
これは、 00001111 というマスクで、 01010101 というデータの上位 4 桁を覆い隠した(マスクした)といえます。
だから、 01010101 を データ と名付け、 00001111 を マスク と名付けたのです。
このようなマスクができるのは、
- 0 と AND 演算をすれば、相手が 0 でも 1 でも 0 になり(必ず 0 になる)
- 1 と AND 演算をすれば、相手が 0 なら 0 になり、相手が 1 なら 1 になる(変化しない)
からです。
納得していただけましたね!
それでは、問題を見てみましょう。
「 8 ビットのビット列の下位 4 ビットが変化しない操作はどれか」
ですから、これは、これまで説明してきた「 00001111 と AND 演算する」です。
選択肢では、 2 進数を 16 進数 表記し、論理演算の種類を日本語で示しています。 00001111 を 16 進数表記すると 0F です。 AND 演算を日本語で示すと 論理積 です。
したがって、選択肢ウの「 16 進数表記 0F のビット列との 論理積 をとる」が正解です。
解答ウ
searchタグで関連記事をチェックマスク
厳選問題looks_two今後の試験で出題比率が多くなる「数学」の問題をやっておこう
ある工場では,同じ製品を独立した二つのライン A,B で製造している。 ライン A では製品全体の 60 % を製造し,ライン B では 40 % を製造している。 ライン A で 製造された製品の 2 % が不良品であり,ライン B で製造された製品の 1 % が不良品で あることが分かっている。 いま,この工場で製造された製品の一つを無作為に抽出して調べたところ,それは不良品であった。 その製品がライン A で製造された確率は何 % か。
ア 40 イ 50 ウ 60 エ 75
基本情報技術者試験を実施している情報処理推進機構のニュースリリースによると
「 2019 年の秋期試験から、午前試験で数学に関する出題比率を見直し、線形代数、確率、統計等、数学に関する出題比率を多くする」
そうです。
info_outline 関連記事
したがって、今後受験を予定されている人は、これまで以上に数学に関する過去問題を数多く練習しておくべきです。 そんなわけで、この問題を取り上げました。
テーマは、「確率」です。
基本情報技術者試験で要求される数学の知識は、だいたい中学レベルです。 何らかの事例に仕立てたような問題が出題されるので、一見して難しそうに感じるかもしれませんが、必ずできますので、自信を持って解いてください。
それでは、やってみましょう。
ライン A は、製品全体の 60 % を製造し、その 2 % が不良品なので、
ライン A の不良品は、全体の
chevron_right0.6 × 0.02 = 0.012 = 1.2 %
です。
ライン B は、製品全体の 40 % を製造し、その 1 % が不良品なので、
ライン B の不良品は、全体の
chevron_right0.4 × 0.01 = 0.004 = 0.4 %
です。
不良品は、全部で
chevron_right1.2 % + 0.4 % = 1.6 %
になります。
無造作に抽出した不良品が ライン A で製造された確率は、全体の不良品の 1.6 % のうち、ライン A の不良品が 1.2 % なのですから、
chevron_right1.2 ÷ 1.6 = 0.75 = 75 %
という計算で求められます。
正解は、選択肢エです。
やったあ! できたあ!
解答エ
厳選問題looks_32 のべき乗は指折り数えて計算しよう
32 ビットで表現できるビットパターンの個数は, 24 ビットで表現できる個数の何倍か。
ア 8 イ 16 ウ 128 エ 256
問題に示された「ビットパターン」とは、 2 進数のデータのパターンのことです。
当然のことですが、ビット数( 2 進数の桁数)が多いほど、表現できるビット数が多くなります。
たとえば、
1 ビットで表現できるビットパターンは、
0 と 1 の 2 通りです。
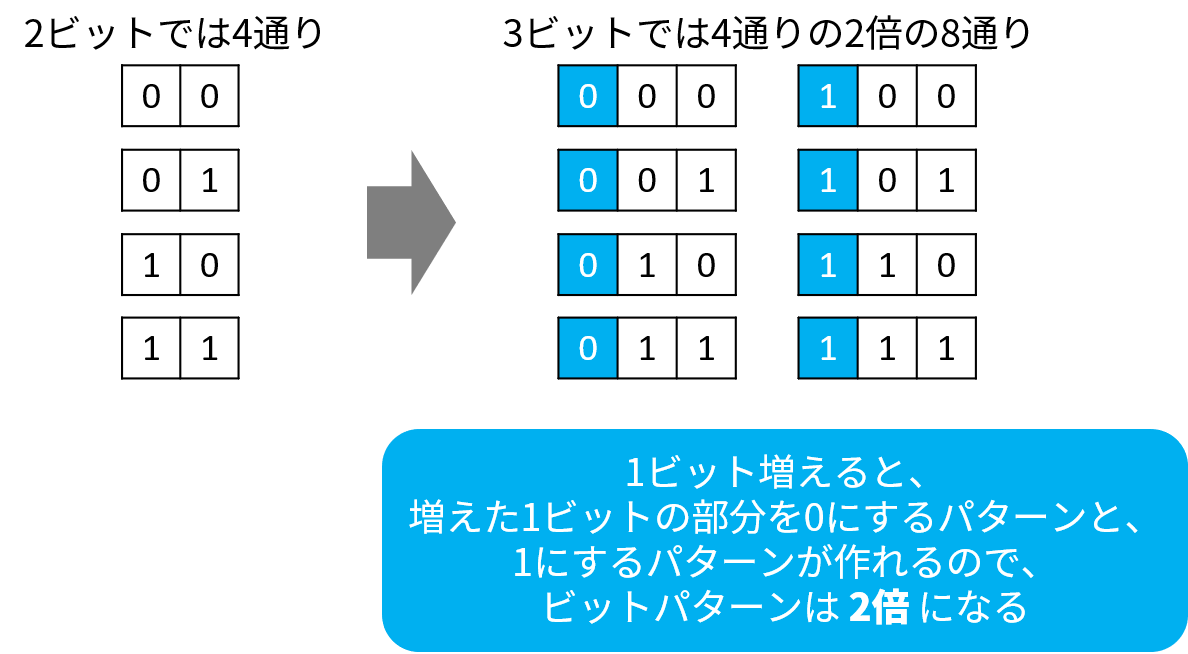
2 ビットで表現できるビットパターンは、
00 、 01 、 10 、 11 の 4 通り です。
3 ビットで表現できるビットパターンは、
000 、 001 、 010 、 011 、 100 、 101 、 110 、 111 の 8 通りです。
1 ビット で 2 通り、 2 ビット で 4 通り、 3 ビット で 8 通りなのですから、 1 ビット増えるごとに、表現できるビットパターンが 2 倍になります。
これまでのビットパターンにもう 1 ビット 増やしたら、増やした部分を 0 にしたビットパターンと、 1 にしたビットパターンが作れるので、 2 倍になって当然です。
以下の図を見て「1 ビット増えるごとに、表現できるビットパターンが 2 倍になる」ということを覚えてください。
それでは、問題を見てみましょう。
32 ビットは、 24 ビットと比べて、 32 – 24 = 8 ビット多いです。 8 ビット多いと何倍になるか、指折り数えてみましょう。
「 2 倍」
「 4 倍」
「 8 倍」
「 16 倍」
「 32 倍」
「 64 倍」
「 128 倍」
「 256 倍」
ですから、 256 倍になります。 したがって、正解は、選択肢エです。
解答エ
searchタグで関連記事をチェック2 のべき乗
厳選問題looks_4A / D 変換に関する 3 つの用語をまとめて覚えよう
標本化,符号化,量子化の三つの工程で、アナログをディジタルに変換する場合の順番として,適切なものはどれか。
ア 標本化,量子化,符号化 イ 符号化,量子化,標本化
ウ 量子化,標本化,符号化 エ 量子化,符号化,標本化
自然界にあるアナログデータを、コンピュータで処理できるディジタルデータに変換することを「 A / D 変換( Analog / Digital 変換)」と呼びます。
基本情報技術者試験によく出る A / D 変換は、音声のアナログデータをディジタルデータに変換することなので、それをイメージするとよいでしょう。
この問題は、 A / D 変換で行われる「標本化」「符号化」「量子化」が、どの順番で行われるかを問うものです。 こういうことは、腕を組んで考えてわかることではありません。 説明を読んで覚えることです。
最初に行われるのは「標本化」です。
日本人が「標本」と聞くと、昆虫採集を思い浮かべるかもしれませんが、これは「サンプリング( sampling )」という英語を日本語に直訳したものです。
標本化は、アナログのデータを一定時間間隔でぶち切れのデータとして記録することです。 記録することを「標本化」と呼んでいるのです。
次に行われるのは「量子化( quantization )」です。
これは、標本化されたデータを、基準となる数値(これが量子です)の整数倍に置き換えることです。 たとえば、 1 を量子とすれば、その整数倍の 1 、 2 、 3 、 4 、 5 、 6 、 7 ・・・にします。
この場合には、たとえば、標本化された 6.5 は 7 に、 5.3 は 5 に量子化するのが適切でしょう。 ここでは、四捨五入して整数にしています。
最後に行われるのは、「符号化( coding )」です。
これは、量子化されたデータを、あらかじめ決めておいた形式の 2 進数のデータ( 2 進数の符号)にすることです。 たとえば、8 ビットにすると決めておいたなら、量子化された 7 は 00000111 に符号化され、 5 は 00000101 に符号化されます。
符号とは、コンピュータで処理できる 2 進数のデータを意味しています。
以上のことから、 A / D 変換の手順は、「標本化」→「量子化」→「符号化」です。
したがって、選択肢アが正解です。
解答ア
searchタグで関連記事をチェック音声サンプリング
厳選問題looks_5とにかくよく出る FIFO 、 LRU 、 LFU の意味をしっかり覚えよう
LRU アルゴリズムで、ページ置換えの判断基準に用いられる項目はどれか。
ア 最後に参照した時刻 イ 最初に参照した時刻
ウ 単位時間当たりの参照頻度 エ 累積の参照回数
この問題を見て「キター!」と思いました。 仮想記憶のページングアルゴリズムである FIFO 、 LRU 、 LFU は、とにかくよく出る問題だからです。
これらは、実メモリ(主記憶)が一杯になったときに、今後使われる可能性が低いページ(記憶領域を固定的なサイズで区切った部分)を、仮想メモリ(補助記憶装置)に追い出すときのアルゴリズムです。
アルゴリズムといっても、処理の手順ではなく、今後使われる可能性が低いページを決める方法のことです。
FIFO 、 LRU 、 LFU は、どれかが優れているというわけではなく、どれもごもっともな方法です。 どれが効果的なのかは、状況次第でしょう。 それぞれの用語が、何の略なのかを知り、それを日本語に直訳して意味を覚えてください。
- FIFO
- First In First Out の略で、「先に入ったものを先に出す」という意味です。
先に実メモリに入ったページは古いのですから、今後使われる可能性が低いと判断するのです。 ごもっともな方法です。
- LRU
- Recently Used の略で、「最近使っていない」という意味です。
最後に使ってから最も時間が経過しているページは、今後使われる可能性が低いと判断するのです。 これも、ごもっともな方法です。 Least は、 Little の最上級で「最も~でない」を意味します。 Recently は、「最近」という意味です。
- LFU
- Least Frequently Used の略で、「頻繁に使っていない」という意味です。
使われた回数が少ないページは、今後使われる可能性が低いと判断するのです。 これも、ごもっともな方法です。 Frequently は、「頻繁に」という意味です。
それでは、問題を見てみましょう。 LRU の判断基準を選ぶのですから「最後に使われた時間」です。
したがって、選択肢アの「最後に参照した時刻」が正解です。
解答ア
info_outlineFIFO / LRU / LFU に関する詳しい記事

記事をお読みいただきありがとうございます。
もしも、一度解いただけでは、よくわからない問題があったなら、わかるまで何度でも練習してください。 「やるべき問題」は「わかるまでやるべき問題」だからです。
この厳選問題大全集が、受験者の皆様のお役に立てば幸いです。
label 関連タグ
免除試験を受けた 74.9% の方が、科目A免除資格を得ています。
※独習ゼミは、受験ナビ運営のSEプラスによる試験対策eラーニングです。

「厳選5題」過去問と解説|令和元年度 秋期 の過去問やるならこれをやれ
update
「厳選5題」過去問と解説|平成31年度 春期 の過去問やるならこれをやれ
update
「厳選5題」過去問と解説|平成21年度 秋期 の過去問やるならこれをやれ
update
「厳選5題」過去問と解説 | 平成22年度 春期 の過去問やるならこれをやれ
update
「厳選5題」過去問と解説 | 平成22年度 秋期 の過去問やるならこれをやれ
update
「厳選5題」過去問と解説 | 平成23年度 春期 の過去問やるならこれをやれ
update
「厳選5題」過去問と解説 | 平成23年度 秋期 の過去問やるならこれをやれ
update
「厳選5題」過去問と解説 | 平成24年度 春期 の過去問やるならこれをやれ
update
「厳選5題」過去問と解説 | 平成24年度 秋期 の過去問やるならこれをやれ
update
「厳選5題」過去問と解説 | 平成25年度 春期 の過去問やるならこれをやれ
update
『プログラムはなぜ動くのか』(日経BP)が大ベストセラー
IT技術を楽しく・分かりやすく教える“自称ソフトウェア芸人”
大手電気メーカーでPCの製造、ソフトハウスでプログラマを経験。独立後、現在はアプリケーションの開発と販売に従事。その傍ら、書籍・雑誌の執筆、またセミナー講師として活躍。軽快な口調で、知識0ベースのITエンジニアや一般書店フェアなどの一般的なPCユーザの講習ではダントツの評価。
お客様の満足を何よりも大切にし、わかりやすい、のせるのが上手い自称ソフトウェア芸人。
主な著作物
- 「プログラムはなぜ動くのか」(日経BP)
- 「コンピュータはなぜ動くのか」(日経BP)
- 「出るとこだけ! 基本情報技術者」 (翔泳社)
- 「ベテランが丁寧に教えてくれる ハードウェアの知識と実務」(翔泳社)
- 「ifとelseの思考術」(ソフトバンククリエイティブ) など多数










