クイックソートのアルゴリズム|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
2023-07-19 更新

基本情報技術者試験は、 2023 年 4 月から新制度で実施されています。
この連載では、新制度で採用された新しい擬似言語(旧制度の擬似言語とは、表記方法に違いがあります)を使って、試験のシラバス(情報処理技術者試験における知識・技能の細目)に示されている代表的なアルゴリズムとデータ構造を、プログラミング入門者向けにやさしく解説します。 受験対策としてだけでなく、アルゴリズムとプログラミングの基礎知識を習得するために、ぜひお読みください。
前回は 再帰呼び出し を取り上げました。 今回は、再帰呼び出しを使った クイックソート を取り上げます。
クイックソートのアルゴリズム
クイックソートは、配列をソートするアルゴリズムの一種です。 クイックソートのアルゴリズムは以下です。
format_quote
グループ分けすることでソートの対象となる配列の要素数が徐々に少なくなることと、プログラムで繰り返しを実現するときに再帰呼び出し(関数や手続の処理の中で、同じ関数や手続を呼び出すことで、繰り返しを実現するプログラミング技法)を使うことが、クイックソートの特徴です。
図 1 は、要素数 7 個の配列(要素番号は 1 から始まるとします)を昇順にクイックソートする手順の例を示したものです。
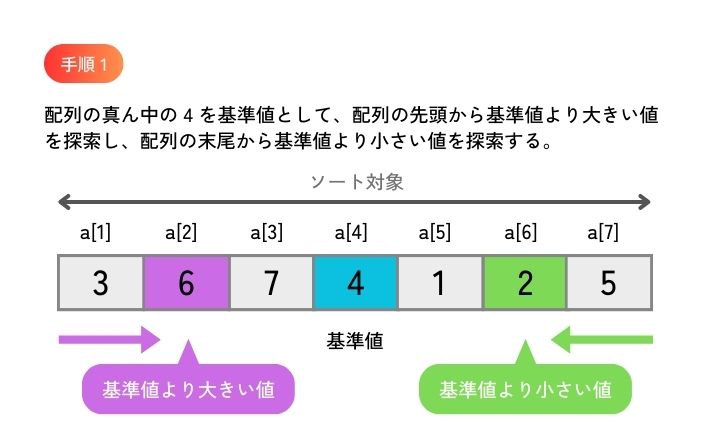
ここでは、ソート対象となる配列の真ん中の要素を基準値としています。
真ん中の要素の要素番号は、
(左端の要素の要素番号 + 右端の要素の要素番号) ÷ 2
という計算で求められます。 要素番号は、整数型のデータなので、除算結果の小数点以下はカットされます。
初期状態(図 1 の【手順 1 】)では、ソート対象となる配列が a[1] ~ a[7] なので、
(1 + 7) ÷ 2 = 4
となり、 a[4] に格納されている 4 が基準値です。
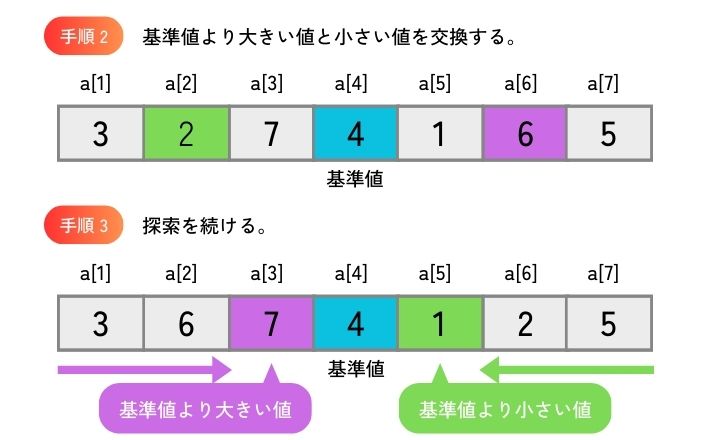
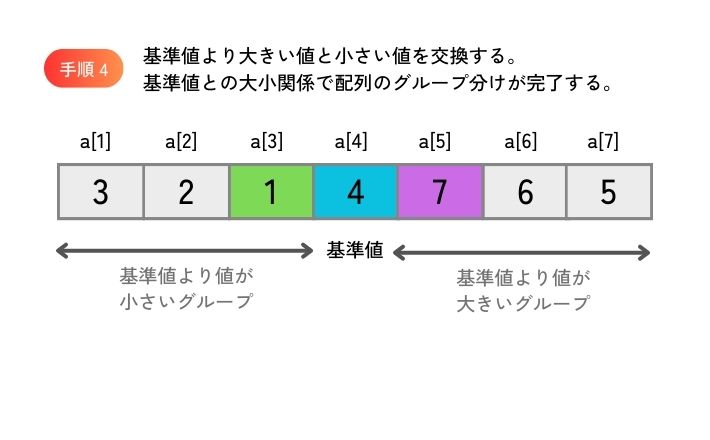
配列の先頭から基準値より大きい値を探索し、配列の末尾から基準値より小さい値を探索して、大きい値と小さい値を交換することを繰り返すと、基準値との大小関係で配列のグループ分けができます。
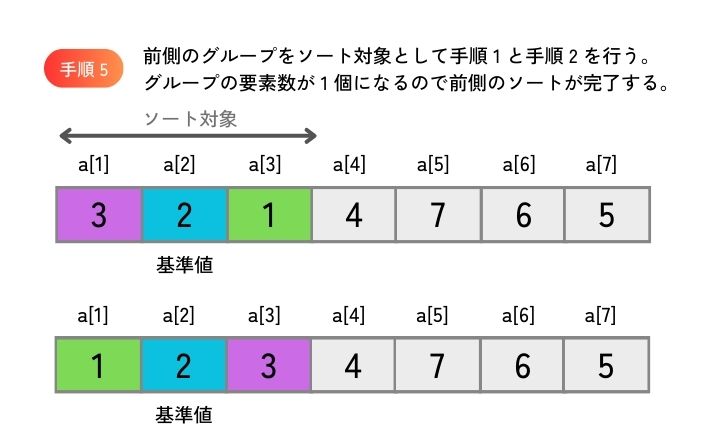
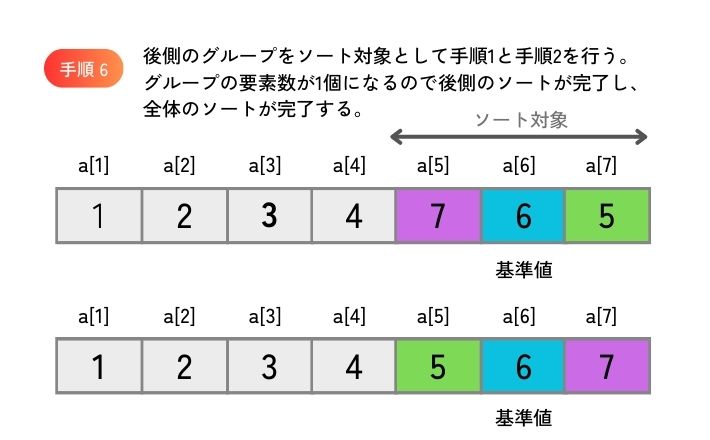
同じ手順を、グループ分けしたそれぞれのグループで繰り返します。 グループの要素数が 1 個になったら繰り返しを終了します。 すべてのグループの繰り返しが終了したら、配列全体のソートが完了します。
クイックソートのプログラム
リスト 1 は、クイックソートのプログラムの例です。
これは、 2023 年 7 月 6 日に情報処理推進機構から公開された「令和 5 年度 基本情報技術者試験 科目 B 公開問題」の問 3 に示されたプログラムに、若干のアレンジを加えたものです。
手続 sort は、配列を昇順にクイックソートします。
引数 a は、ソート対象の配列です。
引数 first は、ソート対象の先頭の要素番号です。
引数 last は、ソート対象の末尾の要素番号です。
配列の要素番号は、 1 から始まるとします。
○sort(整数型の配列: a, 整数型: first, 整数型: last) 整数型 pivot, i, j, temp /* 配列の真ん中の要素を基準値とし 基準値の要素番号を pivot に設定する */ pivot ← a[(first + last) ÷ 2] /* 配列の先頭の要素番号を i に設定する */ i ← first /* 配列の末尾の要素番号を j に設定する */ j ← last /* 無限ループで繰り返す */ while (true) /* 配列の先頭から pivot 以上の要素を探索し、見つかった位置を i に得る */ while (a[i] < pivot) i ← i + 1 endwhile /* 配列の末尾から pivot 以下の要素を探索し、見つかった位置を j に得る */ while (pivot < a[j]) j ← j - 1 endwhile /* 探索の範囲を超えているなら */ if (i ≧ j) /* グループ分けが完了しているので無限ループを抜ける breakは、繰り返しを抜けるメールだとする */ break endif /* 基準値の前側にある基準値以上の a[i] と 基準値の後側にある基準値以下の a[j] を交換する*/ temp ← a[i] a[i] ← a[j] a[j] ← temp endwhile /* グループ分けした前側の要素数が 2 個以上なら */ if (first < i - 1) /* 再帰呼び出しで、前側で同じ処理を繰り返す */ sort(a, first, i - 1) endif /* グループ分けした後側の要素数が 2 個以上なら */ if (j + 1 < last) /* 再帰呼び出しで、後側で同じ処理を繰り返す */ sort(a, j + 1, last) endif
プログラムに多くのコメントを入れてあります。 コメントを参考にして、プログラムの処理内容を読み取ってください。
注目してほしいのは、再帰呼び出しで繰り返しを行っている部分です。 手続 sort は、
「基準値を決め、ソート対象の配列を基準値との大小関係でグループ分けする」
という処理を行います。
この処理を、グループ分けされた前側と後側で繰り返すので、 sort( ソート対象の配列 ) の処理の中で、 sort( 前側のグループ ) と sort( 後側のグループ ) を呼び出すのです。 この部分が、再帰呼び出しです。
グループの要素数が 1 個になるまで( 2 個以上である限り)、この再帰呼び出しを繰り返します。
基本情報技術者試験の公開問題にチャレンジ
最後に、試験対策として「令和 5 年度 基本情報技術者試験 科目 B 公開問題」の問 3 にチャレンジしてみましょう。
基本情報技術者試験の科目 B 試験では、 100 分で 20 問を解きます。 1 問当たりの解答時間の目安は、
100 分 ÷ 20 問 = 5 分
です。
この問題の中には「クイックソート」という言葉はありませんが、クイックソートのプログラムを学んだ経験があれば「あっ! これはクイックソートだ」とすぐにわかり、 5 分程度ですんなり問題を解けるでしょう。 逆に、クイックソートのプログラムを学習した経験がないと、相当な時間がかかるか、まったくお手上げでしょう。
この問題から、試験対策として、シラバスに示されたアルゴリズムとデータ構造をきちんと学ぶことの重要性を感じてください。 「きちんと学ぶ」とは、単にアルゴリズムを理解するだけでなく、実際のプログラムでどのような処理になるのかを経験することです。
次の手続 sort は,大域の整数型の配列 data の,引数 first で与えられた要素番号から引数 last で与えられた要素番号までの要素を昇順に整列する。ここで, first
< last とする。 手続 sort を sort(1, 5) として呼び出すと, /*** α ***/ の行を最初に実行したときの出力は “” となる。
プログラムcode
大域: 整数型の配列: data ← {2, 1, 3, 5, 4}
○sort(整数型: first, 整数型: last)
整数型: pivot, i, j
pivot ← data[(first + last) ÷ 2 の商]
i ← first
j ← last
while (true)
while (data[i] < pivot)
i ← i + 1
endwhile
while (pivot < data[j])
j ← j - 1
endwhile
if (i ≧ j)
繰返し処理を終了する
endif
data[i] と data[j] の値を入れ替える
i ← i + 1
j ← j - 1
endwhile
data の全要素の値を要素番号の順に空白区切りで出力する /*** α ***/
if (first < i - 1)
sort(first, i - 1)
endif
if (j + 1 < last)
sort(j + 1, last)
endif
解答群
ア 1 2 3 4 5
イ 1 2 3 5 4
ウ 2 1 3 4 5
エ 2 1 3 5 4
先ほどリスト 1 に示したプログラムでは、ソート対象の配列を手続 sort の引数で指定していましたが、公開問題のプログラムでは、大域の配列(プログラムのどこからでも使える配列)としています。 これは、プログラムの内容をシンプルにするためでしょう。
このプログラムの処理内容は、リスト 1 に示したプログラムと同様です。 ここでは、
data ← {2, 1, 3, 5, 4}
という配列を最初にグループ分けした後で、 data の全要素の値を要素番号の順に空白区切りで出力した結果を、解答群の中から選びます。
最初のグループ分けでは、
{2, 1, 3, 5, 4}
の 3 を基準値として、配列全体をグループ分けします。
{2, 1, 3, 5, 4}
は、 3 の前に 3 より小さい値があり、 3 の後に 3 より大きい値があるので、要素の値の交換は行われず、このままでグループ分けが完了しています。
したがって、
2 1 3 5 4
と表示されます。 選択肢エが正解です。
今回は、クイックソート取り上げました。
次回以降も、シラバスに示されたアルゴリズムとデータ構造を学んでいきます。
それでは、またお会いしましょう!
info_outline関連記事
免除試験を受けた 74.9% の方が、科目A免除資格を得ています。
※独習ゼミは、受験ナビ運営のSEプラスによる試験対策eラーニングです。

マージソート|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
二分木の深さ優先探索と幅優先探索|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
比べてわかるキューとスタックの仕組み|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
「リスト」というデータ構造|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
サーチのアルゴリズム (3) ハッシュ表探索法のアルゴリズム|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
クイックソートのアルゴリズム|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
再帰呼び出しのアルゴリズム|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
サーチのアルゴリズム (2) 二分探索法|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
サーチのアルゴリズム (1) 線形探索法|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
多重ループを使うバブルソート|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
『プログラムはなぜ動くのか』(日経BP)が大ベストセラー
IT技術を楽しく・分かりやすく教える“自称ソフトウェア芸人”
大手電気メーカーでPCの製造、ソフトハウスでプログラマを経験。独立後、現在はアプリケーションの開発と販売に従事。その傍ら、書籍・雑誌の執筆、またセミナー講師として活躍。軽快な口調で、知識0ベースのITエンジニアや一般書店フェアなどの一般的なPCユーザの講習ではダントツの評価。
お客様の満足を何よりも大切にし、わかりやすい、のせるのが上手い自称ソフトウェア芸人。
主な著作物
- 「プログラムはなぜ動くのか」(日経BP)
- 「コンピュータはなぜ動くのか」(日経BP)
- 「出るとこだけ! 基本情報技術者」 (翔泳社)
- 「ベテランが丁寧に教えてくれる ハードウェアの知識と実務」(翔泳社)
- 「ifとelseの思考術」(ソフトバンククリエイティブ) など多数











