「リスト」というデータ構造|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
2023-11-14 更新

基本情報技術者試験は、2023年4月から新制度で実施されています。
この連載では、新制度の擬似言語(旧制度の擬似言語とは、表記方法に違いがあります)を使って、試験のシラバス(情報処理技術者試験における知識・技能の細目)に示されている代表的なアルゴリズムとデータ構造を、プログラミング入門者向けにやさしく解説します。受験対策としてだけでなく、アルゴリズムとプログラミングの基礎知識を習得するために、ぜひお読みください。
今回は、「リスト」というデータ構造を取り上げます。
もくじ
リストとは?
試験のシラバスには、代表的なデータ構造として、配列、リスト、キュー、スタック、二分探索木、ヒープなどが示されていますが、どのデータ構造も、その実体は配列です。他のデータ構造は、配列の使い方にプログラムで様々な工夫を加えることで実現されています。
今回のテーマであるリスト(連結リストとも呼びます)は、配列の個々の要素が次の要素へのつながり情報を持ったものです。このつながり情報のことをポインタとも呼びます。次の要素を指し示す(ポイントする)ものだからです。
配列(リストではない通常の配列)とリストの違いを説明しましょう。
例として、東海道新幹線の東京から新大阪まで、のぞみ号が停車する駅名を、配列とリストで表してみます。
配列の場合は、要素番号(先頭の要素番号を1とします)の順に要素をたどるので、東京から新大阪までの駅名を要素番号の順に格納します(図1)。

「品川がない」と気づかれたと思いますが、後の説明の都合で入れていません。
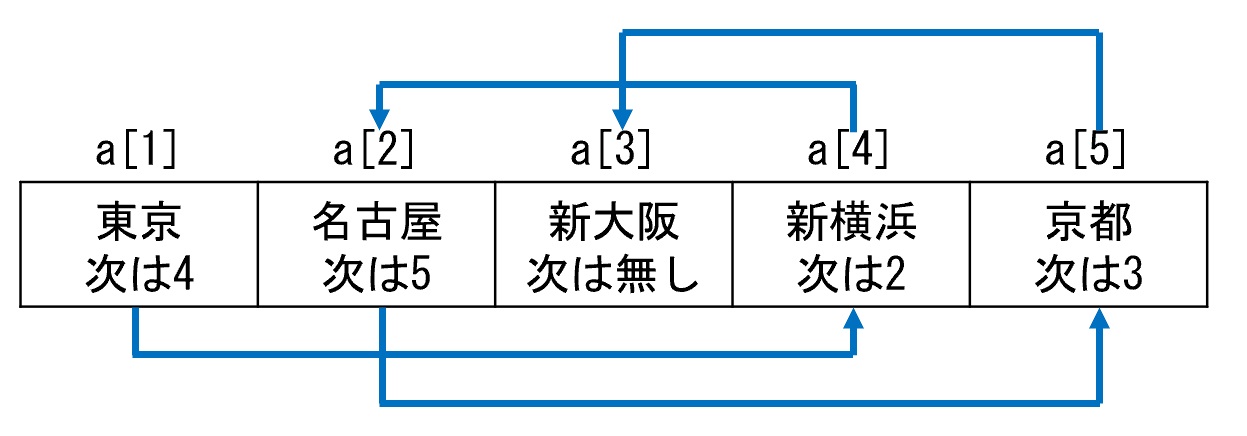
リストの場合は、個々の要素が持つつながり情報(次の要素の要素番号やアドレス)で要素をたどるので、要素の格納順は任意で構いません(図2)。
配列と比べて、リストには、要素の挿入が効率的にできるという長所があります。
先ほど図1と図2に示した例に、品川を挿入してみましょう。
配列の場合は以下の手順です(図3)
- 新横浜以降の要素を1つずつ後ろにずらす
- a[2] の位置に品川を挿入
※要素をずらす処理に時間がかかります。

リストの場合は以下の手順です(図4)
- 配列の末尾のa[6]に品川を追加
- 東京の「次は4」を「次は6」に更新
- 品川に「次は4」を設定
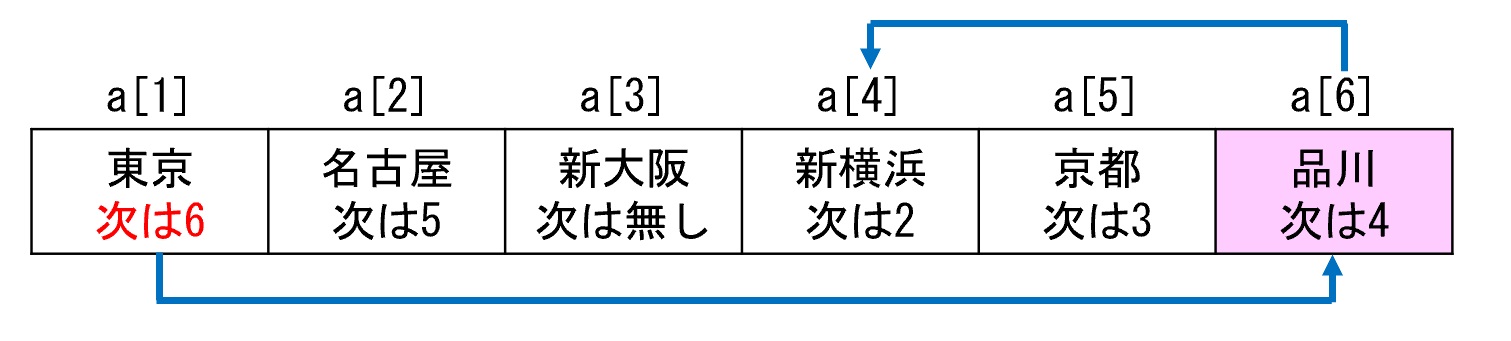
これだけで、東京と新横浜の間に品川を挿入できます。要素をずらす処理が不要なので時間がかかりません。
リストでは、要素の削除も、つながり情報の更新だけで済むので、配列より効率的です。
リストをプログラムで実現する方法
リストをプログラムで実現するには、データの値とつながり情報を要素とした配列を定義します。基本情報技術者試験のサンプル問題や公開問題では、これをクラスとして実現しています。クラスは、オブジェクトの定義であり、複数のデータと複数の処理をまとめたモジュール(プログラムの部品)です。
ここでは、駅のリストの要素を表すStationクラスを定義することにします。
擬似言語では、クラスが持つデータをメンバ変数と呼び、クラスが持つ処理をメソッドと呼びます。
Stationクラスには、駅名を示すメンバ変数name、次の要素のアドレスを格納するメンバ変数next、および新たな要素を作成するコンストラクタStationがあるとします。コンストラクタは、特殊なメソッドであり、クラス名と同名のメソッドにします。これまでの例では、要素番号をつながり情報としていましたが、ここでは、メモリ上に要素を新たに作成していくので、要素のメモリアドレスをつながり情報とします。
まず、品川なしで、東京→新横浜→名古屋→京都→新大阪というリストを作成しましょう。
以下にプログラムを示します。
プログラムcode
Station:listHead // リストの先頭の要素のアドレスを格納する変数
Station:cur // 現在の処理対象の要素のアドレス格納する変数
Station:temp // 一時的にアドレスを格納する変数(後で使います)
cur ← Station("東京") // 東京の要素を作成し処理対象とする
listHead ← cur // 先頭の要素を東京とする
cur.next ← Station("新横浜") // 新横浜の要素を作成し東京の次とする
cur ← cur.next // 新横浜を処理対象とする
cur.next ← Station("名古屋") // 名古屋の要素を作成し新横浜の次とする
cur ← cur.next // 名古屋を処理対象とする
cur.next ← Station("京都") // 京都の要素を作成し名古屋の次とする
cur ← cur.next // 京都を処理対象とする
cur.next ← Station("新大阪") // 新大阪の要素を作成し京都の次とする
cur ← cur.next // 新大阪を処理対象とする
cur.next ← 未定義の値 // 新大阪の次を無し(未定義の値)とする
要素のアドレスを格納する変数のデータ型は、Stationクラスにします。
変数listHeadには、リストの先頭の要素のアドレスを格納します。
変数cur(current=「現在の」という意味です)には、現在の処理対象となっている要素のアドレスを格納します。
個々の要素が持つメンバ変数は「要素名.メンバ変数名」という構文で指定します。
cur.nextは、次の要素のアドレス(つながり情報)を示します。
cur ← cur.nextは、現在の次の要素を、新たな処理対象にします
次に、東京と新横浜の間に品川を挿入してみましょう。
lishHeadから、つながり情報で要素をたどり、駅名が東京なら、その要素と次の要素の間に品川を挿入します。
コメントを参考にしながら、以下のプログラム(先ほどのプログラムの続きだとします)を読み取ってください。
プログラムcode
cur ← listHead // リストの先頭の要素を処理対象とする
while (cur.next ≠ 未定義の値) // 末尾の要素まで繰り返す
if (cur.name = "東京") // 現在の要素が東京なら品川を挿入する
temp ← cur.next // 東京の次のアドレスをtempに逃がしておく
cur.next ← Station("品川") // 品川の要素を作成し東京の次とする
cur ← cur.next // 品川を処理対象とする
cur.next ← temp // 逃がしておいたアドレスを品川の次に設定する
繰り返し処理を抜ける // 繰り返しを抜ける
endif
cur ← cur.next // 次の要素を処理対象とする
endwhile
ここでは、繰り返し処理を抜ける処理を「繰り返し処理を抜ける」という日本語の文章で示しています。サンプル問題や公開問題でも、同様の表現が使われているからです。
基本情報技術者試験の公開問題にチャレンジ
最後に、試験対策として、2022年4月に公開(8月に一部改訂)された科目Bサンプル問題の問3にチャレンジしてみましょう。
これは、リストへの要素の追加をテーマにした問題です。
リストに要素を追加する手続appendの処理内容を読み取ってください。問題文の中にある「インスタンスの参照」とは、要素のアドレスという意味です。
問3 次のプログラムの中の[ a ]と[ b ]に入れる正しい答えの組み合わせを、解答群の中から選べ。
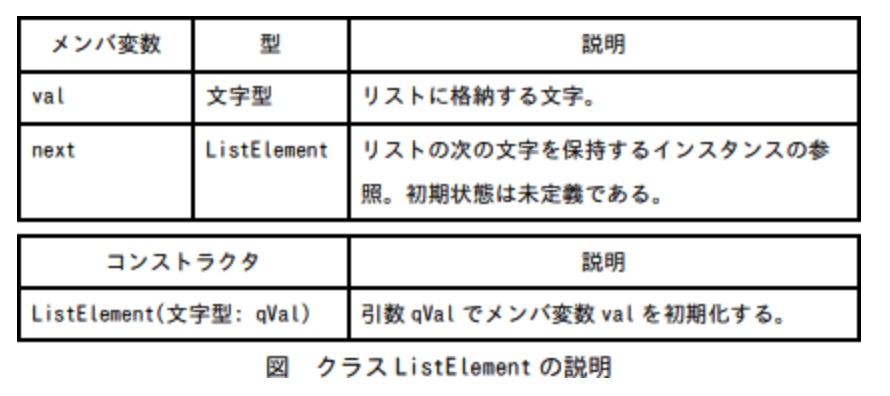
手続 append は,引数で与えられた文字を単方向リストに追加する手続である。単方向リストの各要素は,クラス ListElement を用いて表現する。クラス ListElement の説明を図に示す。ListElement 型の変数はクラス ListElement のインスタンスの参照を格納するものとする。大域変数 listHead は,単方向リストの先頭の要素の参照を格納する。リストが空のときは,listHead は未定義である。

大域変数(プログラムのどこからでも利用できる変数)listHeadには、初期値として、未定義の値が格納されています。これは、リストが空の状態であるということです。
手続appendは、引数qValの値を持つ要素をリストに追加します。
appendの最初の処理として、引数qValを格納した要素を新たに作成し、そのアドレスを変数currに格納しています。
次に、もしもlistHeadの値が空欄aなら、大域変数listHeadに変数currを代入しています。これは、新たに作成した要素をリストの先頭にする処理なので、最初の要素を挿入する場合です。listHeadの値が未定義の値なら、最初の要素だと判断できるので、空欄aは、未定義の値です。これで、正解を解答群の選択肢ア、イ、ウに絞り込めました。
空欄bがあるelseブロックは、最初の要素でない場合の処理なので、リストの末尾の要素の次に、新たに作成した要素を追加します。
そのために、変数prev(previous=「前の」という意味です)に大域変数listHeadの値を格納し、「prev.nextが未定義でない」という条件のwhileブロックで繰り返し処理を行います。この処理では、変数prevにprev.nextを格納して、リストをたどっています。これが「prev.nextが未定義でない」という条件が真である限り繰り返されるので、繰り返しを抜けたときには、変数prevに既存のリストの末尾の要素のアドレスが得られます。
その要素の次を意味するメンバ変数prev.nextに、新たに作成した要素のアドレスを格納すれば、リストに要素を追加できるので、空欄bはcurrです。
以上のことから、選択肢アが正解です。
解答:ア
☆ ☆ ☆
今回は、リストを取り上げました。
次回以降も、シラバスに示されたアルゴリズムとデータ構造を学んでいきます。
それでは、またお会いしましょう!
label 関連タグ免除試験を受けた 74.9% の方が、科目A免除資格を得ています。
※独習ゼミは、受験ナビ運営のSEプラスによる試験対策eラーニングです。

マージソート|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
二分木の深さ優先探索と幅優先探索|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
比べてわかるキューとスタックの仕組み|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
「リスト」というデータ構造|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
サーチのアルゴリズム (3) ハッシュ表探索法のアルゴリズム|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
クイックソートのアルゴリズム|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
再帰呼び出しのアルゴリズム|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
サーチのアルゴリズム (2) 二分探索法|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
サーチのアルゴリズム (1) 線形探索法|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
多重ループを使うバブルソート|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
『プログラムはなぜ動くのか』(日経BP)が大ベストセラー
IT技術を楽しく・分かりやすく教える“自称ソフトウェア芸人”
大手電気メーカーでPCの製造、ソフトハウスでプログラマを経験。独立後、現在はアプリケーションの開発と販売に従事。その傍ら、書籍・雑誌の執筆、またセミナー講師として活躍。軽快な口調で、知識0ベースのITエンジニアや一般書店フェアなどの一般的なPCユーザの講習ではダントツの評価。
お客様の満足を何よりも大切にし、わかりやすい、のせるのが上手い自称ソフトウェア芸人。
主な著作物
- 「プログラムはなぜ動くのか」(日経BP)
- 「コンピュータはなぜ動くのか」(日経BP)
- 「出るとこだけ! 基本情報技術者」 (翔泳社)
- 「ベテランが丁寧に教えてくれる ハードウェアの知識と実務」(翔泳社)
- 「ifとelseの思考術」(ソフトバンククリエイティブ) など多数








