サーチのアルゴリズム (3) ハッシュ表探索法のアルゴリズム|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
2023-08-03 更新

基本情報技術者試験は、 2023 年 4 月から新制度で実施されています。
この連載では、新制度で採用された新しい擬似言語(旧制度の擬似言語とは、表記方法に違いがあります)を使って、試験のシラバス(情報処理技術者試験における知識・技能の細目)に示されている代表的なアルゴリズムとデータ構造を、プログラミング入門者向けにやさしく解説します。 受験対策としてだけでなく、アルゴリズムとプログラミングの基礎知識を習得するために、ぜひお読みください。
今回は、サーチのアルゴリズムの 3 つめとして「ハッシュ表探索法」を取り上げます。
info_outline他のサーチアルゴリズムの記事
計算量が O(1) になる理由
計算量を表すオーダー表記
アルゴリズムの良し悪しを示す尺度として「計算量」というものがあります。
計算量には、いくつかの表記方法がありますが、よく使われるのは「オーダー表記」と呼ばれるものです。 これは、データ数の増加に対して処理回数がどのように増えるかを「 O( n の式) 」
という表記で示したものです。この O は、 order (次数、規模)の頭文字です。
たとえば、単純なループ(一重のループ)を使う線形探索法の計算量は、
O(n)
です。 n の 1 次式なので、線形探索法の処理回数は、データが 10 倍になれば 10 倍になり、 100 倍になれば 100 倍になります。
多重ループ(二重のループ)を使うバブルソートの計算量は、
O(n2)
です。 n の 2 次式なので、バブルソートの処理回数は、データが 10 倍になれば 100 倍になり、 100 倍になれば 10000 倍になります。
ハッシュ表探索法の計算量
それでは、今回のテーマであるハッシュ表探索法の計算量はいくつなのかというと、理想的には
O(1)
です。
この 1 は、ハッシュ表探索法の処理回数は、データ数に関わらず 1 回であることを意味しています。 「理想的には」と但し書きを入れているのは、 1 回より多くなる場合もあり得るからです。それに関しては、後で説明します。
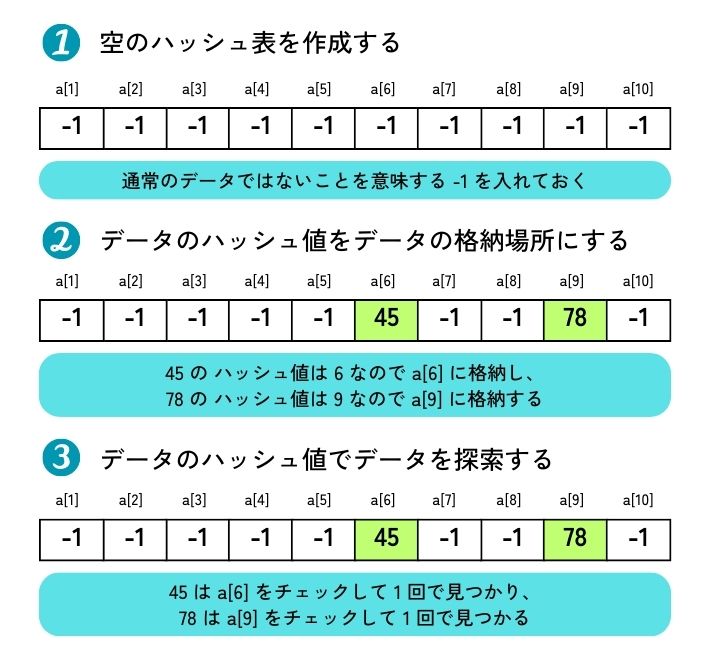
ハッシュ表探索法では、データの値からデータの格納場所を決める「ハッシュ関数」を用意しておきます。
たとえば、要素数 10 個の配列 a[1] ~ a[10] (後でチャレンジする公開問題に合わせて、配列の要素番号は 1 から始まるとします)に、正の整数データを格納するなら、
データの値 mod 10 + 1
というハッシュ関数を用意し、このハッシュ関数で得られた値(「ハッシュ値」と呼びます)をデータの格納場所にします。 データの値 mod 10 + 1 で得られる値は 1 ~ 10 になるので、格納場所は配列 a[1] ~ a[10] の範囲に収まります。
たとえば、 45 というデータは、
45 mod 10 + 1 = 6
なので a[6] に格納します。
78 というデータは、
78 mod 10 + 1 = 9
なので a[9] に格納します。
このようにしてデータを格納した表を「ハッシュ表」と呼び、ハッシュ表を使った探索を「ハッシュ表探索法」と呼ぶのです。 ハッシュ( hash )は、「切り刻む」や「ごった混ぜにする」という意味です。
このハッシュ表から、たとえば 45 というデータを探索するには、
45 mod 10 + 1 = 6
なので a[6] をチェックします。 a[6] には 45 が格納されているので 1 回の処理で見つかります。
同様に、 78 というデータを探索するには、
78 mod 10 + 1 = 9
なので a[9] をチェックして 1 回の処理で見つかります。 これが、ハッシュ表探索法で計算量が
O(1)
になる理由です。
なお、データが格納されていない要素には、それがわかるように、通常のデータではないことを意味する値を入れておきます。 ここでは、データが正の整数なので、 0 や -1 などを入れておけばよいでしょう(図 1 )。
シノニムに対処する方法
ハッシュ表探索法の計算量は、理想的に O(1) です。 ここで、理想的というのは、ハッシュ表に格納するデータ群の中に、同じハッシュ値になるデータ(これを「シノニム( synonym = 同義語、類義語)」と呼びます)がない場合です。
もしも、シノニムがあると、それに対処するための処理が必要になり、 1 回ではデータが見つかりません。
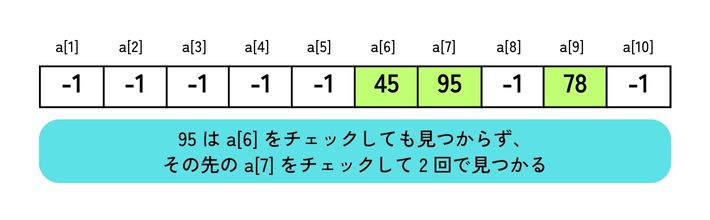
たとえば、先ほど図 1 の 3 に示したハッシュ表に、 95 を格納するとしましょう。 95 のハッシュ値は、
95 mod 10 + 1 = 6
であり、すでに a[6] に格納されている 45 と同じになります。 95 はシノニムであり、ハッシュ値の a[6] に格納できません。
シノニムに対処する方法は、いくつか考えられますが、単純な方法は、ハッシュ値で得た格納場所より先(末尾を超えた場合は先頭に戻る)で最初に空いている場所に格納する方法です。
ここでは、 a[6] より先で最初に空いている( -1 が格納されている)のが a[7] なので、そこに 95 を格納します。 この場合には、 95 は 1 回では見つかりません(図 2 )。
基本情報技術者試験の公開問題にチャレンジ
最後に、試験対策として「令和 5 年度 基本情報技術者試験 科目 B 公開問題」の問 4 にチャレンジしてみましょう。
ハッシュ表探索をテーマにした問題であり、シノニムの対処もあります。
問 4
次の記述中のに入れる正しい答えを,解答群の中から選べ。ここで,配列の要素番号は 1 から始まる。
関数 add は,引数で指定された正の整数 value を大域の整数型の配列 hashArray に格納する。格納できた場合は true を返し,格納できなかった場合は false を返す。
ここで,整数 value を hashArray のどの要素に格納すべきかを,関数 calcHash1 及び calcHash2 を利用して決める。
手続 test は,関数 add を呼び出して,hashArray に正の整数を格納する。手続 test の処理が終了した直後の hashArray の内容は,である。
プログラムcode
大域: 整数型の配列: hashArray
○論理型: add(整数型: value)
整数型: i ← calcHash1(value)
if (hashArray[i] = -1)
hashArray[i] ← value
return true
else
i ← calcHash2(value)
if (hashArray[i] = -1)
hashArray[i] ← value
return true
endif
endif
return false
○整数型: calcHash1(整数型: value)
return (value mod hashArrayの要素数) + 1
○整数型: calcHash2(整数型: value)
return ((value + 3) mod hashArrayの要素数) + 1
○test()
hashArray ← {5 個の -1}
add(3)
add(18)
add(11)
解答群
ア {-1, 3, -1, 18, 11}
イ {-1, 11, -1, 3, -1}
ウ {-1, 11, -1, 18, -1}
エ {-1, 18, -1, 3, 11}
オ {-1, 18, 11, 3, -1}
プログラムの内容を説明しましょう。
ここでは、要素数 5 個の整数型の配列 hashArray がハッシュ表であり、そこに正の整数 value を格納します。
- hashArray のすべての要素には、初期値として、データが格納されていないことを意味する -1 が格納されています
- 関数 test では、引数 value の値を 3 、 18 、 11 として、ハッシュ表にデータを格納する関数 add を 3 回呼び出しています
- ハッシュ関数は、 2 つ用意されています
- 関数 calcHash1 は
value mod 5 + 1という計算でハッシュ値を得ます - 関数 calcHash2 は
(value + 3) mod 5 + 1という計算でハッシュ値を得ます
- 関数 calcHash1 は
- 関数 add は、関数 calcHash1 で得た場所が空いているなら、そこに value を格納して true を返し、空いていないなら、関数 calcHash2 で得た場所が空いているなら、そこに value を格納して true を返し、そこも空いていないなら、 false を返します。
関数 add の戻り値は、データを格納できたら true であり、格納できなかったら false です
擬似言語の表記で示すと、初期状態のハッシュ表の内容は
{-1, -1, -1, -1, -1}
です。
最初の 3 は、関数 calcHash1 で得た
3 mod 5 + 1 = 4
の場所が空いてるので、そこに格納され、ハッシュ表の内容は
{-1, -1, -1, 3, -1}
になります。
次の 18 は、関数 calcHash1 で得た 18 mod 5 + 1 = 4 の場所が空いていないので、そこには格納せず、関数 calcHash2 で得た
(18 + 3) mod 5 + 1 = 2
の場所が空いてるので、そこに格納され、ハッシュ表の内容は
{-1, 18, -1, 3, -1}
になります。
最後の 11 は、関数 calcHash1 で得た 11 mod 5 + 1 = 2 の場所が空いていないので、そこには格納せず、関数 calcHash2 で得た
(11 + 3) mod 5 + 1 = 5
の場所が空いてるので、そこに格納され、ハッシュ表の内容は
{-1, 18, -1, 3, 11}
になります。
以上のことから、選択肢エが正解です。
今回は、ハッシュ表探索法を取り上げました。
次回以降も、シラバスに示されたアルゴリズムとデータ構造を学んでいきます。
それでは、またお会いしましょう!
label 関連タグ免除試験を受けた 74.9% の方が、科目A免除資格を得ています。
※独習ゼミは、受験ナビ運営のSEプラスによる試験対策eラーニングです。

マージソート|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
二分木の深さ優先探索と幅優先探索|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
比べてわかるキューとスタックの仕組み|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
「リスト」というデータ構造|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
サーチのアルゴリズム (3) ハッシュ表探索法のアルゴリズム|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
クイックソートのアルゴリズム|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
再帰呼び出しのアルゴリズム|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
サーチのアルゴリズム (2) 二分探索法|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
サーチのアルゴリズム (1) 線形探索法|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
多重ループを使うバブルソート|新しい擬似言語で学ぶ 科目 B アルゴリズムとプログラミング入門
update
『プログラムはなぜ動くのか』(日経BP)が大ベストセラー
IT技術を楽しく・分かりやすく教える“自称ソフトウェア芸人”
大手電気メーカーでPCの製造、ソフトハウスでプログラマを経験。独立後、現在はアプリケーションの開発と販売に従事。その傍ら、書籍・雑誌の執筆、またセミナー講師として活躍。軽快な口調で、知識0ベースのITエンジニアや一般書店フェアなどの一般的なPCユーザの講習ではダントツの評価。
お客様の満足を何よりも大切にし、わかりやすい、のせるのが上手い自称ソフトウェア芸人。
主な著作物
- 「プログラムはなぜ動くのか」(日経BP)
- 「コンピュータはなぜ動くのか」(日経BP)
- 「出るとこだけ! 基本情報技術者」 (翔泳社)
- 「ベテランが丁寧に教えてくれる ハードウェアの知識と実務」(翔泳社)
- 「ifとelseの思考術」(ソフトバンククリエイティブ) など多数










