午後問題の歩き方 | 午後問題の読み方~データベース 「 SQL と正規化」
2021-09-15 更新

error
この記事は基本情報技術者試験の旧制度( 2022 年以前)の記事です。
この記事の題材となっている「午後問題」は現在の試験制度では出題されません。 ご注意くださいませ。
データベースの問題は、「 SQL 」と「正規化」を勉強しておけば OK という傾向があります。
ここでは、 平成 22 年度 秋期 午後 問 2 を例にして、 SQL と 正規化 に関して、具体的に何を知っていればよいかを説明しましょう。
しっかりとポイントをつかんで、データベースの問題を得点源にしてください。
error本記事ではわかりやすいよう、問題文に文字に色やシンタックスハイライトなどを入れています
もくじ
正規形と正規化の定義をきちんと覚えておく
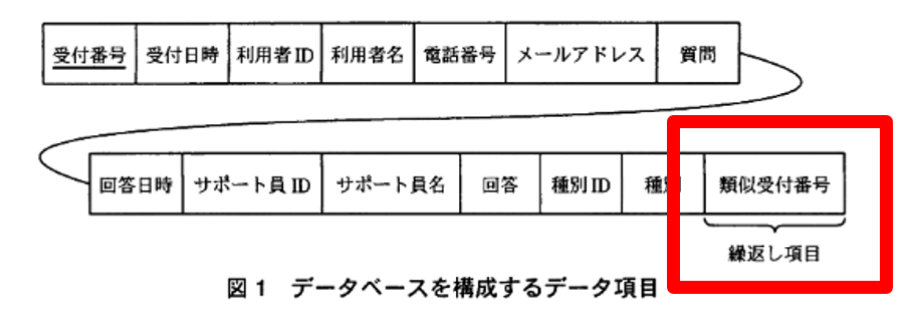
以下は、問題の冒頭部分です。細かいことは気にせずに、図 1 を見てください。
データベースを構成するデータ項目を抽出したところ、「類似受付番号」という繰り返し項目が生じました。ここで、すぐにピンと来てほしいのですが、 「繰り返し項目がある」は、非正規形の定義 です。
したがって、このあとに、正規形や正規化に関する設問があるはずです。
コールセンターの対応記録管理に関する次の記述を読んで,設問 1 ~ 4 に答えよ。
F 社では,新しいソフトウェア製品の発売と同時に,そのソフトウェア製品に関する質問を受けるコールセンターを開設することにした。コールセンターでの対応内容は,すべてデータベースに記録する。
[コールセンターの業務]
- (1)
- 製品を購入した利用者には,一意な利用者 ID が発行されている。質問を受ける際は,この利用者 ID を通知してもらう。
- (2)
- 対応内容をデータベースに記録する際,その質問の原因を特定する種別を設定する。種別とは “マニュアル不備” , “使用法誤解” などの情報である。それぞれの種別に対して一意に種別 ID を割り当てる。
- (3)
- データベースを検索し,過去に同じ種別 ID をもつ類似の質問があった場合は,その受付番号を類似受付番号として記録しておく。
図 1 は,これらの業務を基に,データベースを構成するデータ項目を抽出したものである。下線付きの項目は主キーを表す。
設問 1 を見てみると、やはり正規化がテーマでした。
以下の図 2 は、図 1 を正規化した結果です。そして、空欄 a, b, c には、第 1 正規化、第 2 正規化、第 3 正規化 において行う作業が入ります。
ここで注意してほしいのは、この問題は、図 1 と図 2 を比較して答えるものではないということです。
空欄と選択肢を、よく見てください。正規形 と 正規化の定義 を知っているだけで、答えを選べる 内容になっています。
図 1 に示したデータ項目を正規化して図 2 に示す表を設計し,運用を始めた。 実施した正規化に関する説明文のに入れる正しい答えを,解答群の中から選べ。
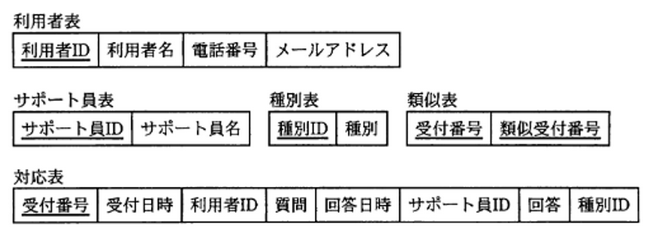
図 1 に示した状態は非正規形と呼ばれ,1 事実 1 か所の関係が成立していないので,重複更新,事前登録,関係喪失などの問題がある。このため,第 1 正規化 から順に第 3 正規化までを行うことにした。
まず,第 1 正規化の作業では, a 。次に,第 2 正規化の作業では, b。そして,第 3 正規化の作業では, c。
解答群
- ア
- 受付番号と類似受付番号の組合せを主キーとして 繰返し要素を排除した
- イ
- 既に当該正規形に準じていたので,適用は不要だった
- ウ
- データ参照時の処理性能を考慮し,質問と回答を一つの表で管理するようにした
- エ
- 利用者表,サポート員表及び種別表を作成し,主キー以外の項目における関数従属性を排除した
- オ
- 類似表を作成し,主キーの一部における関数従属性を排除した
「繰り返し項目がある」が、非正規形の定義であり、 「繰り返し項目を排除する」が 第 1 正規化の作業 です。第 1 正規化によって、第 1 正規形になります。
したがって、空欄 a の答えは、選択肢アの「繰り返し要素を排除した」です。
「第 1 正規形を満たし、さらに 部分従属性を排除したもの」が、第 2 正規形の定義 であり、「部分従属性を排除する」が、第 2 正規化の作業です。
部分従属性とは、複数の項目をセットにして主キー(複合キー)としている場合に、主キーの一部分の項目だけに従属した項目があることです。従属(関数従属)とは、ある項目によって他の項目を特定できるということです。
したがって、空欄 b の答えは、選択肢オの「主キーの一部における関数従属性を排除した」です。
「第 2 正規形を満たし、 さらに推移従属性を排除したもの」が、第 3 正規形の定義 であり、「推移従属性を排除する」が、第 3 正規化の作業です。
推移従属性とは、主キーでない項目に従属した項目があることです。
したがって、空欄 c の答えは、選択肢エの「主キー以外の項目における関数従属性を排除した」です。
| 正規化の段階 | やること |
|---|---|
| 第 1 正規化 | 繰り返し項目を排除する |
| 第 2 正規化 | 部分従属性を排除する |
| 第 3 正規化 | 推移従属性を排除する |
これまでの記事でも、何度か説明してきましたが、基本情報技術者試験のシラバス(出題されるテーマの細目)は、午前問題と午後問題で分けられていません。
したがって、午前問題をしっかり練習しておけば、午後問題も必ず解けます。
午後問題は、午前問題で取り上げられる基礎知識を、架空の事例に仕立てたものです。見かけは難しそうでも、設問の内容は、午前問題と変わりません。
「きっと解けるはずだ!」と、自信を持って取り組んでください。
info_outline正規化をわかりやすく解説した記事ができました

午前問題を数多く練習して SQL を覚える
データベースでは、とにかく SQL の問題がよく出題されます。
info_outline参考記事

4 データベースの出題傾向(午後問 2 ~問 4 )
この問題でも、設問 2, 設問 3, 設問 4 は、どれも SQL の問題です。試験対策では、過去の試験に出題された SQL を覚えることが効率的です。基本情報技術者試験は、「基本」なのですから、基本的な SQL しか出題されません。
どこまでが基本なのかは、実際に出題された SQL を見なければわかりません。
そのために、 SQL に関する午前問題を、数多く練習しておくことをお勧めします。
たとえば、以下は、平成 25 年度 春期 午前 問 29 です。
“BOOKS” 表から書名に “UNIX” を含む行を全て探すために次の SQL 文を用いる。
a に指定する文字列として,適切なものはどれか。ここで,書名は “BOOKS” 表の “書名” 列に格納されている。
SELECT * FROM BOOKS WHERE 書名 LIKE '[ a ]'
ア %UNIX イ %UNIX% ウ UNIX エ UNIX%
「 % 」が 0 文字以上の任意の文字列を意味するので、 書名 LIKE '% UNIX %' という表現で、「書名に UNIX という文字列を含む」という条件を表せます。
したがって、答えは、選択肢イです。
それでは、午後問題を見てみましょう。以下は、設問 2 です。
ある利用者から “オプションの指定方法” に関する質問を受けた。過去に類似の質問があったかどうかを確認するため,”オプション” というキーワードを含む質問をすべて抽出する。次の SQL 文の に入れる正しい答えを,解答群の中から選べ。
SELECT 対応表.受付番号, 利用者表.利用者名, 対応表.質問
FROM 対応表, 利用者表
WHERE 対応表.利用者ID = 利用者表.利用者ID
AND '[ ]'
解答群
ア 質問 ANY (‘%オプション%’) イ 質問 ANY (‘_オプション_’)
ウ 質問 IN (‘%オプション%’) エ 質問 IN (‘_オプション_’)
オ 質問 LIKE ‘%オプション%’ カ 質問 LIKE ‘_オプション_’
先ほどの午前問題で得た知識があれば、質問に「オプション」というキーワードを含むという条件は、「質問 LIKE ‘%オプション%’ 」だとわかります。
答えは、選択肢オです。
選択肢の定番のパターンを知っておく
SQL の問題の選択肢には、定番のパターンがあります。おそらく、出題者は、過去問題を見て、選択肢の作り方を参考にしているのでしょう。
以下は、設問 3 です。
製品のバージョンアップに当たり, コールセンターの対応記録を参考にして機能改善を検討することにした。種別が “使用法誤解” であった質問を抽出し, 類似件数の多い順に表示する。次の SQL 文のに入れる正しい答えを, 解答群の中から選べ。
SELECT 類似受付番号, COUNT(*) FROM 対応表, 種別表, 類似表
WHERE '[ ]'
ORDER BY COUNT(*) DESC
解答群
ア
対応表.種別ID = (SELECT 種別ID FROM 種別表 WHERE 種別 = '使用法誤解')
GROUP BY 類似表.類似受付番号
イ
対応表.種別ID = (SELECT 種別ID FROM 種別表 WHERE 種別 = '使用法誤解')
AND 対応表.受付番号 = 類似表.受付番号 GROUP BY 類似表.受付番号
ウ
対応表.種別ID = 種別表.種別ID AND 対応表.受付番号 = 類似表.受付番号
AND 種別表.種別 = '使用法誤解' GROUP BY 類似表.受付番号
エ
対応表.種別ID = 種別表.種別ID AND 対応表.受付番号 = 類似表.受付番号
AND 種別表.種別 = '使用法誤解' GROUP BY 類似表.類似受付番号
SELECT 文 の FROM の部分に注目してください。FROM 対応表, 種別表, 類似表となっていて、複数(ここでは 3 つ)の表が指定されています。
複数の表を関連付けてデータを読み出すには、WHERE の後の条件として、表 と 表のどの項目 が一致するのかを指定しなければなりません。 間違いの選択肢には、その条件が抜けているのです。
これが、定番のパターンです。
選択肢ウとエにある対応表.種別ID = 種別表.種別ID AND 対応表.受付番号 = 類似表.受付番号は、表 と 表のどの項目 が一致するのかを指定するものです。
選択肢アとイには、これがないので、間違いだとわかります。
さらに注目してほしいのは、間違いである選択肢アとイでは、副問い合わせ( WHERE の後にある SELECT 命令)があり、いかにも立派な内容になっています。
このように、間違いの選択肢で副問い合わせを使う のも、定番のパターンです。覚えておいてください。
副問い合わせ (サブクエリ) とは
SQL の中に SQL があることを言い、この問題の、例えば 選択肢アをに入れると、以下のようになります。
SELECT 類似受付番号, COUNT(*) FROM 対応表, 種別表, 類似表
WHERE 対応表.種別ID = (SELECT 種別ID FROM 種別表 WHERE 種別 = '使用法誤解') GROUP BY 類似表.類似受付番号
ORDER BY COUNT(*) DESC
選択肢の違いに注目する
間違いの選択肢を消して、正解を選択肢ウとエに絞れたら、それぞれのどこが違うかに注目してください。
両者の違いは、 GROUP BY 句のあとが選択肢ウが「類似表.受付番号」であり、選択肢エが「類似表.類似受付番号」であることだけです。これらの違いだけに注目して、どちらが適切かを判断してください。
ウ 対応表.種別ID = 種別表.種別ID AND 対応表.受付番号 = 類似表.受付番号 AND 種別表.種別 = '使用法誤解' GROUP BY 類似表.受付番号 エ 対応表.種別ID = 種別表.種別ID AND 対応表.受付番号 = 類似表.受付番号 AND 種別表.種別 = '使用法誤解' GROUP BY 類似表.類似受付番号
GROUP BY でグループ化したときに SELECT の後に指定できる項目は、そのグループに対する集約関数( SUM 関数、AVG 関数、MAX 関数、MIN 関数、COUNT 関数 など)か、グループ化した項目だけです。
これは、常識的に考えて当然のことでしょう。
たとえば、社員を性別でグループ化したら、それぞれのグループの 平均給与( AVG 関数)や 性別(男性か女性か)しか SELECT できません。それぞれのグループから 氏名 を SELECT するのはおかしなことです。
ここでは、SELECT 類似受付番号, COUNT(*) なので、「 GROUP BY 類似表.類似受付番号」の選択肢エが適切です。
わからない SQL が出題されたら英語の意味で素直に考える
いよいよ最後の設問 4 です。選択肢の SQL を見て、面食らうかも知れません。
ALTER TABLE という命令は、過去問題にほとんど出題されたことがないからです。この問題で、ALTER TABLE を初めて見る人もいることでしょう。
見たことのないような命令が答えであることは滅多にないのですが、この問題では、何とビックリ ALTER TABLE を使っている選択肢アが正解 なのです。
新たに提供する製品に関する質問を記録するために, 現在の表に製品型番の列を追加して製品を識別できるようにする。表の拡張と同時に, これまで蓄積した情報の製品型番の列にはすべて “A001” を設定する。正しい SQL 文を, 解答群の中から選べ。
解答群
ア ALTER TABLE 対応表 ADD 製品型番 CHAR(4) DEFAULT 'A001' NOT NULL イ ALTER TABLE 対応表 MODIFY 製品型番 CHAR(4) DEFAULT 'A001' NOT NULL ウ CREATE TABLE 対応表 (製品型番 CHAR(4) DEFAULT 'A001') エ INSERT INTO 対応表 製品型番 VALUES 'A001'
このような問題を解くには、まず、自分の知っている知識の範囲で、間違いだと判断できる選択肢を消しましょう。
「現在の表に製品型番の列を追加する」のですから、新しい表を作成する CREATE TABLE(選択肢ウ)や、表にデータを登録する INSERT INTO(選択肢エ)ではないはずです。
したがって、答えを選択肢アとイに絞り込めます。
選択肢アとイの違いは、ADD と MODIFY だけです。
先ほどの設問 3 でも説明したように、これらの違いだけに注目して、どちらが適切かを判断してください。
ADD は「追加する」という意味であり、MODIFY は「変える」という意味です。「現在の表に製品型番の列を追加する」のですから、ADD が適切だとわかります。
このように、もしも知らない命令が登場したら、知っている知識で答えを絞り込み、あとは英語の意味で判断してください。
ただし、この問題を練習したのですから、 ALTER TABLE という命令の意味を覚えてください。
繰り返しますが、試験対策では、過去の試験に出題された SQL を覚えることが効率的だからです。
info_outlineSQL をわかりやすく解説した記事ができました

label 関連タグ
免除試験を受けた 74.9% の方が、科目A免除資格を得ています。
※独習ゼミは、受験ナビ運営のSEプラスによる試験対策eラーニングです。

基本情報 プログラミング 言語の選択と学習方法|午後問題の歩き方
update
基本情報のサンプル問題で Python の基礎知識をチェック | 午後問題の歩き方
update
「基本情報 の Python ってどんな感じ?」を解説|午後問題の歩き方
update
矢沢久雄さんが執筆! 午後 プログラミング 問題対策の参考書「速習言語」を刊行しました!!
update
こうすりゃ解ける! 2019年度秋期 (令和元年度) 基本情報技術者試験の午後問題を徹底解説
update
こうすりゃ解ける! 2019年度春期 (平成31年度) 基本情報技術者試験の午後問題を徹底解説
update
こうすりゃ解ける! 2018年度秋期 (平成30年) 基本情報技術者試験の午後問題を徹底解説
update
午後問題の歩き方 | 試験1週間前にやるべき午後問題の知識チェック (チェックシート付き)
update
午後問題の歩き方 | Java プログラミング問題の楽勝パターン(2)オブジェクト指向
update
午後問題の歩き方 | Java プログラミング問題の難易度(1)Java基本構文
update
『プログラムはなぜ動くのか』(日経BP)が大ベストセラー
IT技術を楽しく・分かりやすく教える“自称ソフトウェア芸人”
大手電気メーカーでPCの製造、ソフトハウスでプログラマを経験。独立後、現在はアプリケーションの開発と販売に従事。その傍ら、書籍・雑誌の執筆、またセミナー講師として活躍。軽快な口調で、知識0ベースのITエンジニアや一般書店フェアなどの一般的なPCユーザの講習ではダントツの評価。
お客様の満足を何よりも大切にし、わかりやすい、のせるのが上手い自称ソフトウェア芸人。
主な著作物
- 「プログラムはなぜ動くのか」(日経BP)
- 「コンピュータはなぜ動くのか」(日経BP)
- 「出るとこだけ! 基本情報技術者」 (翔泳社)
- 「ベテランが丁寧に教えてくれる ハードウェアの知識と実務」(翔泳社)
- 「ifとelseの思考術」(ソフトバンククリエイティブ) など多数









