Python で ディープラーニング 入門 研修コースに参加してみた

今回参加した研修コースは Python で ディープラーニング入門 です。
SEカレッジでも AI 、Python の関連コースが増えましたね。ビジネス、体験寄り、実装寄りと出てきています。
先日 IPA から AI 人材のモデルが発表されていたので、それに合わせてコースも分類ができそうです。
| AI 研究者 |
|
| AI 開発者 |
|
| AI 事業企画 |
|
このモデルですと、今回のコースは AI 開発者 の エントリーレベル の さらに 入り口 といったところでしょうか。
実際、参加してみると、Python や機械学習などの知識なしに、今回利用する Chainer や TensorFlow, Keras, PyTorch などディープラーニングのフレームワークを使うとは、どういったものなのか、使う側のコードを解説いただいて、そのレベル感のようなものが掴めました!
では、どんな内容だったのか、レポートします!!
なお、 PFN は chainer を fork して開発された PyTorch に移行・コミットするとあわせて発表しています。
もくじ
コース情報
| 想定している受講者 | なし |
| 受講目標 |
|
今日やること
- AI 、モデルがどう出来上がるのか、それを理解して欲しい
- Python の基本構文を学ぶ訳ではありません
講師紹介
前回レポートした「工数見積もり -実践編-」につづき、 藤丸 卓也 さん が登壇されました。

研修コースに参加してみた
藤丸さんは、AI については、実開発だけでなく、資格にも取り組まれています。
- G検定 (JDLA Deep Learning for GENERAL | 主催:一般社団法人 日本デイープラーニング協会[JDLA]) GENERAL の資格を取得
- 藤丸さん談: E資格 (JDLA Deep Learning for ENGINEER ) もありますが、ちょっとお金がかかります
G検定については、弊社のセールススタッフが資格取得したので、記事掲載しています。
ぜひご覧くださいませ~

ディープラーニング とは
ディープラーニングの定義などは、別の参加してみたレポートでも書いていますので、ぜひそちらをご覧くださいませ。

研修コースに参加してみた

研修コースに参加してみた
CNNとRNN
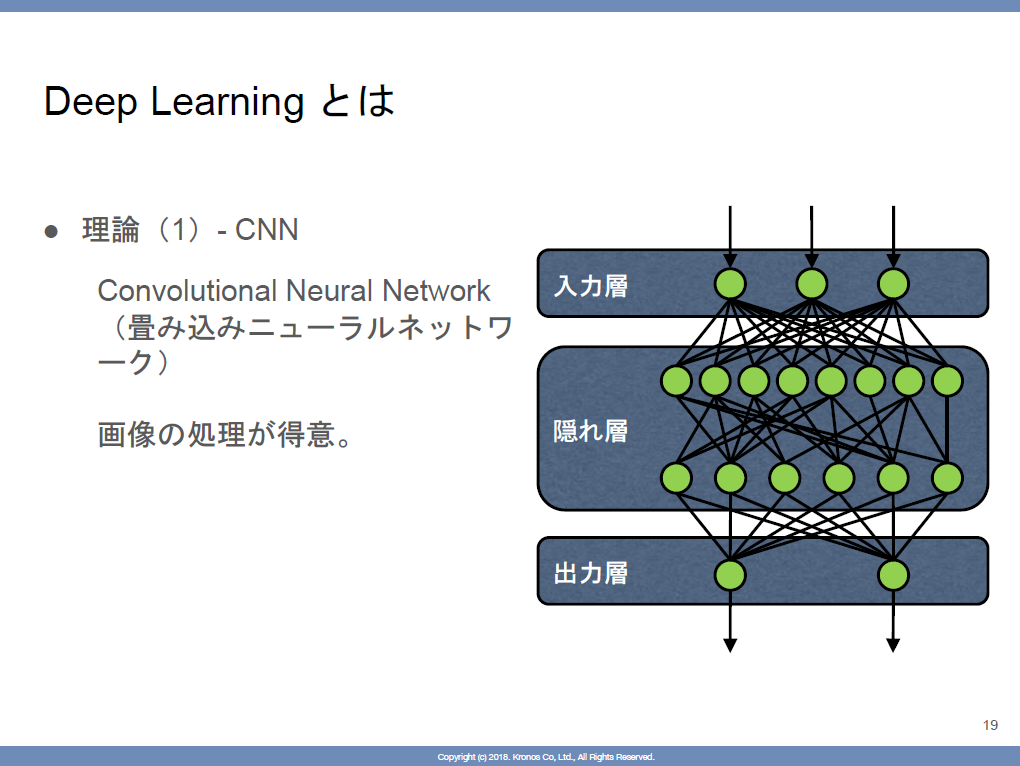
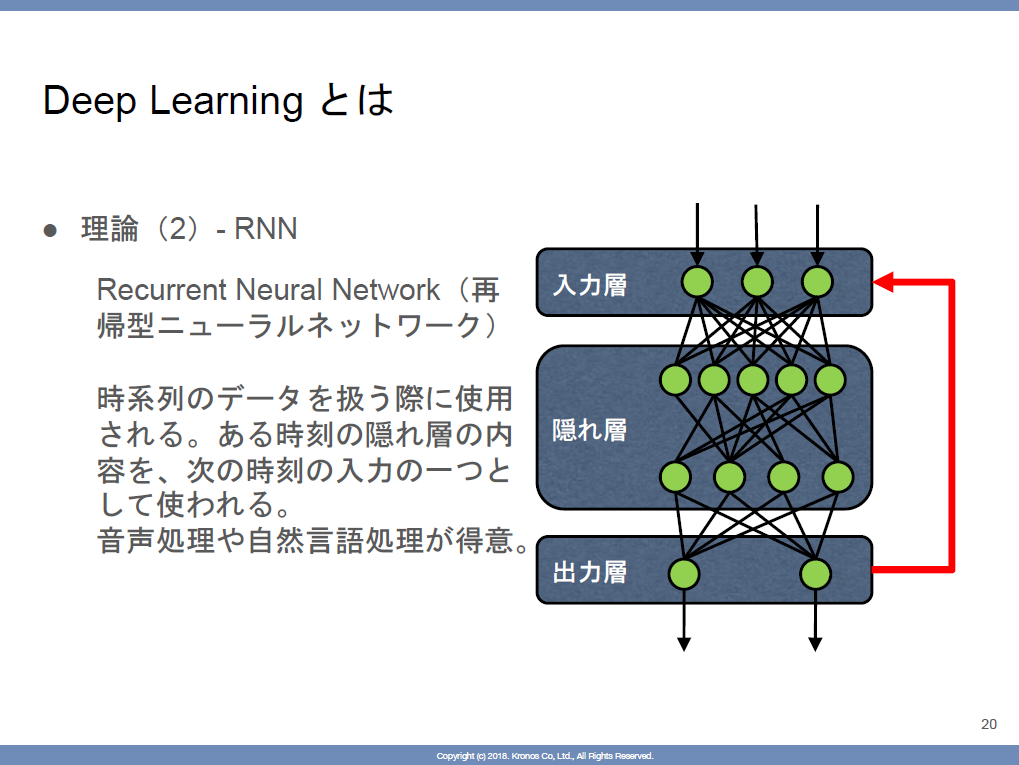
- 共通
- 隠れ層で計算する
- この層を多重にして計算する
- CNN
- 画像処理が強い
- RNN
- 音声処理や自然言語処理が得意
機械学習の仕組み
学習
- 大量のデータ (だいたい 1 万件以上) をもとに特徴を捉える
- ex. 猫を覚えさせるためには、だいたい猫の画像1万枚ぐらいのデータが必要
- データの量にもよるが、1 日ぐらいかかる
- このフェーズでは検証まで含む
- 1 万件データがあったとすると 7000 件を学習データ / 学習で使っていない 3000 件のデータで検証する
推論
- 推論は学習したデータをもとに、新たに与えた画像が、猫かどうかを判定する
今日はこの学習と推論、2 つを Chainer を使って行います。
学習のパターン
- 教師あり学習
- 今日はこのパターンを使います
- 正解ラベルがついたデータ
- 「この画像は猫だよ」というラベル
- 教師なし学習
- 分類のみで使われる
- ザックリいうとラベルをつけるイメージ
- 様々な画像をもとに、形や色などの特徴から分類をつくる
- GAN (敵対生成学習 [Generative Adversarial Networks])
- pix2pix というアルゴリズムを使う
- ある画像から、その特徴を掴んだオリジナルの画像が生成される
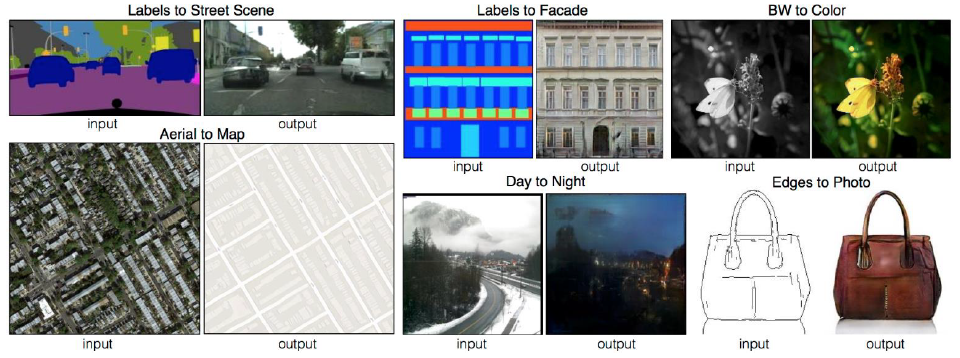
(出展 Image-to-Image Translation with Conditional Adversarial Networks)
Chainer とは
では、今日使用する Chainer について紹介してます。
- PFI / PFNが開発したディープラーニングのフレームワーク
- Facebookがフォークしたことでも有名 -> PyTorch (GitHub スター数 28.6k)
- Chainer のスター数が 4.8k … 😢😢😢
- Pythonですべて書かれている
- ニューラルネットワーク (NN) のアルゴリズムがだいたい揃っている
- Facebookがフォークしたことでも有名 -> PyTorch (GitHub スター数 28.6k)
Chainer の話題では、2019 年 4 月 10 日のリリースで、PFN がオンライントレーニング (日本語) を無償公開し、大きな反響を呼びました。
数学 (微分、線形代数、確率・統計) の基礎や、Python の基礎、NumPy 等のライブラリを使った機械学習入門など、とにかく体系的に、網羅された内容です。
環境構築 (Windows)
- Python のインストール
- Anaconda 3 をインストール
- Visual Studio Build Tools 2017 をインストール
- Chainer をインストール
- pip という Python のライブラリ管理ツールでインストール
GPU
- ディープラーニングと言っても、特別なハードウェアが必要ではない
- が、学習する際に GPU 搭載サーバがあると時間を短縮できる
- 今日の環境は残念ながら CPU
教室では、すでにクラウド上の仮想環境で構築済みなので、スムーズに演習をスタートします。
演習開始
では、実際にオープンデータを使って、ディープラーニングを体験してみます。
- MNIST という学習データを使って学習してみる
- 有名なデータセット。標準で組み込まれている

コンソールから下を実行して MNIST のデータを学習させました。
> python train_mnist.py -g -1 -e 3
GPU: -1
# unit: 1000
# Minibatch-size: 100
# epoch: 3
C:\ProgramData\Anaconda3\lib\site-packages\chainer\optimizers\adam.py:111: Runti
meWarning: invalid value encountered in sqrt
param.data -= hp.eta * (self.lr * m / (numpy.sqrt(vhat) + hp.eps) +
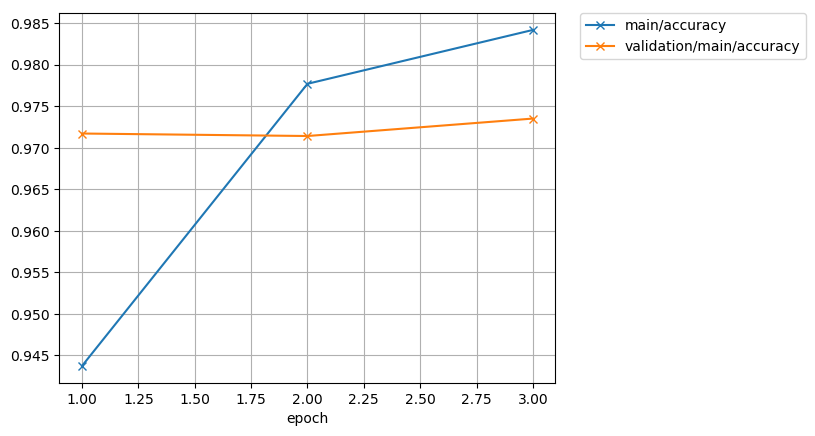
epoch main/loss validation/main/loss main/accuracy validation/main/acc
uracy elapsed_time
C:\ProgramData\Anaconda3\lib\site-packages\chainer\optimizers\adam.py:111: Runti
meWarning: invalid value encountered in sqrt
param.data -= hp.eta * (self.lr * m / (numpy.sqrt(vhat) + hp.eps) +
1 0.189386 0.088241 0.943733 0.9717 188.366
2 0.0725646 0.0875341 0.977683 0.9714 378.107
3 0.049227 0.0849267 0.984167 0.9735 564.709実行したコードの解説
先程、実行したコードを、コメントされた部分をたどりながら、解説いただきます。

#!/usr/bin/env python
import argparse
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import training
from chainer.training import extensions
# Network definition
class MLP(chainer.Chain):
def __init__(self, n_units, n_out):
super(MLP, self).__init__()
with self.init_scope():
# the size of the inputs to each layer will be inferred
self.l1 = L.Linear(None, n_units) # n_in -> n_units
self.l2 = L.Linear(None, n_units) # n_units -> n_units
self.l3 = L.Linear(None, n_out) # n_units -> n_out
def forward(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)
# さっきのコマンドでつけたオプション -g -e などの内容
def main():
parser = argparse.ArgumentParser(description='Chainer example: MNIST')
parser.add_argument('--batchsize', '-b', type=int, default=100, help='Number of images in each mini-batch')
parser.add_argument('--epoch', '-e', type=int, default=20, help='Number of sweeps over the dataset to train')
parser.add_argument('--frequency', '-f', type=int, default=-1, help='Frequency of taking a snapshot')
parser.add_argument('--gpu', '-g', type=int, default=-1, help='GPU ID (negative value indicates CPU)')
parser.add_argument('--out', '-o', default='result', help='Directory to output the result')
parser.add_argument('--resume', '-r', default='', help='Resume the training from snapshot')
parser.add_argument('--unit', '-u', type=int, default=1000, help='Number of units')
parser.add_argument('--noplot', dest='plot', action='store_false', help='Disable PlotReport extension')
args = parser.parse_args()
print('GPU: {}'.format(args.gpu))
print('# unit: {}'.format(args.unit))
print('# Minibatch-size: {}'.format(args.batchsize))
print('# epoch: {}'.format(args.epoch))
print('')
# Model の生成
# Set up a neural network to train
# Classifier reports softmax cross entropy loss and accuracy at every
# iteration, which will be used by the PrintReport extension below.
model = L.Classifier(MLP(args.unit, 10)) # 10 は最終的にアウトプットする値の個数
if args.gpu >= 0:
# Make a specified GPU current
chainer.backends.cuda.get_device_from_id(args.gpu).use()
model.to_gpu() # Copy the model to the GPU
# Setup an optimizer
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
# 以降で Iterator を生成
# Load the MNIST dataset
train, test = chainer.datasets.get_mnist()
train_iter = chainer.iterators.SerialIterator(train, args.batchsize)
test_iter = chainer.iterators.SerialIterator(test, args.batchsize, repeat=False, shuffle=False)
# Trainer の生成
# Set up a trainer
updater = training.updaters.StandardUpdater(train_iter, optimizer, device=args.gpu)
trainer = training.Trainer(updater, (args.epoch, 'epoch'), out=args.out)
# Evaluate the model with the test dataset for each epoch
trainer.extend(extensions.Evaluator(test_iter, model, device=args.gpu))
# Dump a computational graph from 'loss' variable at the first iteration
# The "main" refers to the target link of the "main" optimizer.
trainer.extend(extensions.dump_graph('main/loss'))
# Take a snapshot for each specified epoch
frequency = args.epoch if args.frequency == -1 else max(1, args.frequency)
trainer.extend(extensions.snapshot(), trigger=(frequency, 'epoch'))
# Write a log of evaluation statistics for each epoch
trainer.extend(extensions.LogReport())
# Save two plot images to the result dir
if args.plot and extensions.PlotReport.available():
trainer.extend(extensions.PlotReport(
['main/loss', 'validation/main/loss'], 'epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(
['main/accuracy', 'validation/main/accuracy'], 'epoch', file_name='accuracy.png'))
# Print selected entries of the log to stdout
# Here "main" refers to the target link of the "main" optimizer again, and
# "validation" refers to the default name of the Evaluator extension.
# Entries other than 'epoch' are reported by the Classifier link, called by
# either the updater or the evaluator.
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'validation/main/loss', 'main/accuracy', 'validation/main/accuracy', 'elapsed_time']))
# Print a progress bar to stdout
trainer.extend(extensions.ProgressBar())
if args.resume:
# Resume from a snapshot
chainer.serializers.load_npz(args.resume, trainer)
# Run the training
trainer.run()
if __name__ == '__main__':
main()実行結果の解説
続いて、実行した結果をどのように見るのか、こちらも解説いただきました。
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time
1 0.189386 0.088241 0.943733 0.9717 188.366
2 0.0725646 0.0875341 0.977683 0.9714 378.107
3 0.049227 0.0849267 0.984167 0.9735 564.709- result というディレクトリが出来ている
- ここにグラフなどが入っている
ただ、学習モデルを作ったはずなんですが、表示されません。
このため、先の train_mnist.py に追記します。
# Run the training
trainer.run()
# ここから書き足す
# Save the trained model
chainer.serializers.save_npz("trained_mnist.model", model)
if __name__ == '__main__':
main()これで学習済みモデルができました。

推論してみよう
実際に画像を作って、推論してみます。
(お絵かきの才能…)

- 用意されていた、推論するためのプログラム
import chainer import chainer.functions as F import chainer.links as L from PIL import Image import numpy as np import matplotlib.pyplot as plt class MLP(chainer.Chain): def __init__(self, n_units, n_out): super(MLP, self).__init__() with self.init_scope(): self.l1 = L.Linear(None, n_units) # n_in -> n_units self.l2 = L.Linear(None, n_units) # n_units -> n_units self.l3 = L.Linear(None, n_out) # n_units -> n_out def __call__(self, x): h1 = F.relu(self.l1(x)) h2 = F.relu(self.l2(h1)) return self.l3(h2) model = L.Classifier(MLP(1000, 10)) chainer.serializers.load_npz('trained_mnist.model', model) image = Image.open("number.png").convert('L') plt.imshow(image, cmap='gray') plt.title('input data') plt.show() image = np.asarray(image).astype(np.float32) / 255 image = image.reshape((1, -1)) result = model.predictor(chainer.Variable(image)) print('predicted', ':', np.argmax(result.data)) for i in range(10): print (str(i) , ":" , str(result.data[0,i]))
実行してみます!!
(base) C:\Users\Secollege160405\Desktop\mnist>python predict_mnist.py
predicted : 3
0 : -17.519121
1 : -6.611537
2 : -3.5029051
3 : 28.767323
4 : -16.44517
5 : 0.56008315
6 : -28.957706
7 : -5.5690756
8 : -3.870232
9 : -4.1418304
(base) C:\Users\Secollege160405\Desktop\mnist>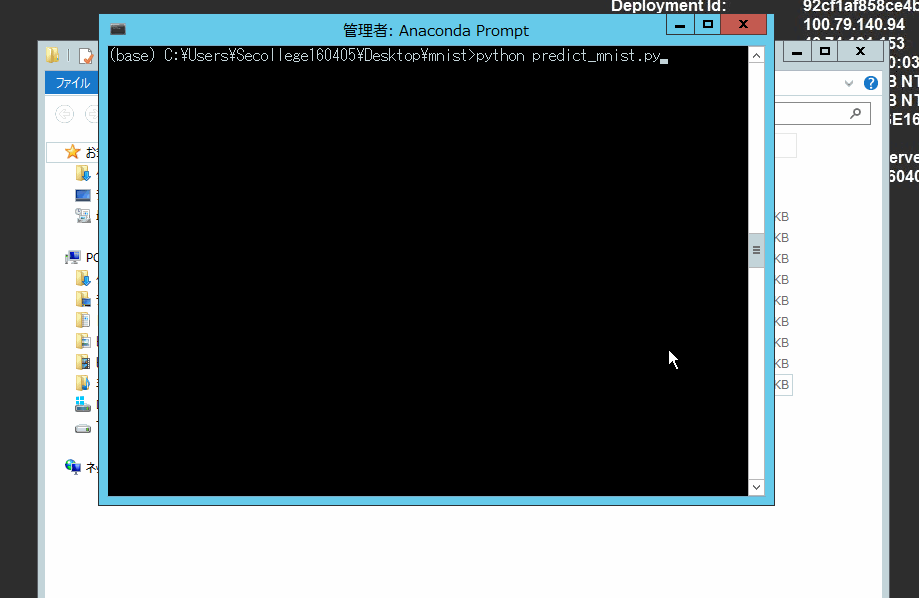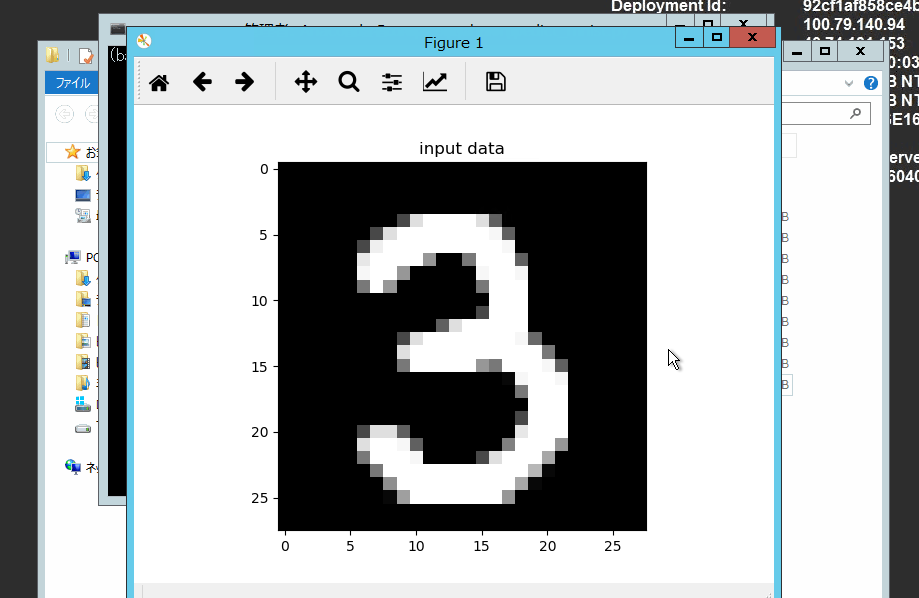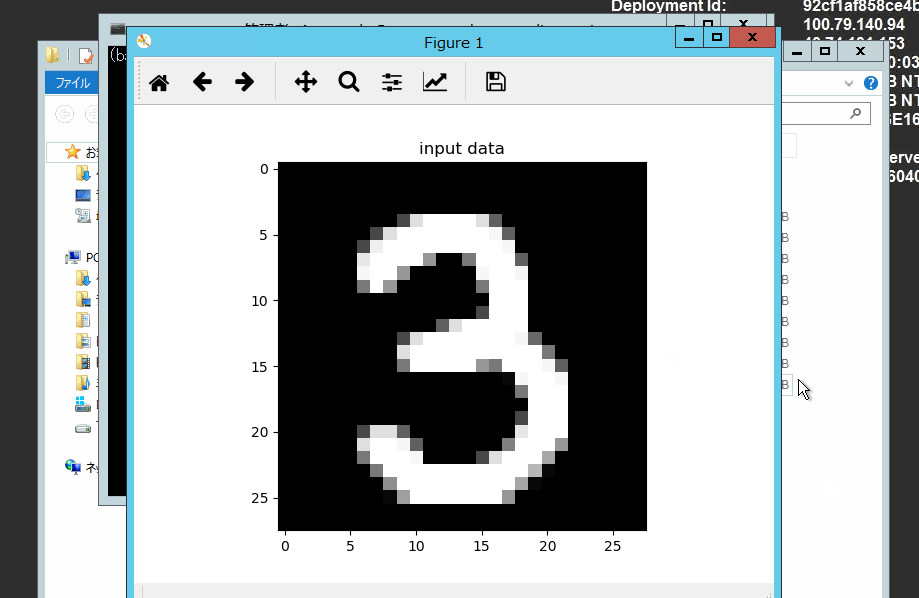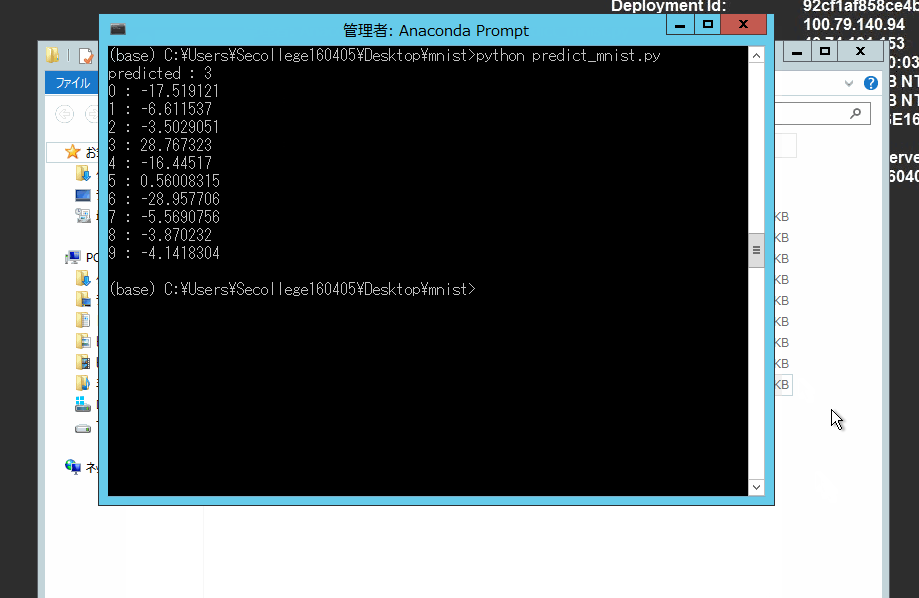
おおー! 「 3 」 と認識されましたね。
ちなみに、1 : ~ 9 : は、それぞれ 1 ~ 9 に見えるかどうかのスコアです。3 が一番高いスコアですね。
まとめ
このコースでは、ディープラーニングを知識や概念だけでなく、実際にオープンデータセットを使って、Chainer で推論できる学習モデルを体験してみました。
また、学習用・推論用の Python のコードも、ブロックごとに丁寧に解説いただいたため、書けるとは言ってませんが、Chainer や TensorFlow 、Keras 、PyTorch などフレームワークを利用する側の、処理の流れは掴めました。
もちろん、NN の定義や、Trainer の作成など、使う側にも相応のデータサイエンスの知識は必要というのもわかりますが、なにかブラックボックスのように「恐れてしまう」ということは無さそうです。
AI やディープラーニングというと、興味はあるけど、数学やフレームワークの敷居がとっても高そう、ということを思ってしまう方には、とてもいいエントリーコースだと思います。
label SE カレッジの無料見学、資料請求などお問い合わせはこちらから!!
label SEカレッジを詳しく知りたいという方はこちらから !!
IT専門の定額制研修 月額28,000円 ~/ 1社 で IT研修 制度を導入できます。
年間 670 講座をほぼ毎日開催中!!
SEプラスにしかないコンテンツや、研修サービスの運営情報を発信しています。