AIのこれまでとこれから 研修コースに参加してみた

今回参加した研修コースは AIのこれまでとこれから です。
いよいよ、この “参加してみた” レポートでもAI登場です。
SEカレッジでも PythonでDeep Learning、Pythonを使ったデータ・サイエンス実践 など実装寄りのコースを開催していますが、このコースは実装ではなく、どちらかというとビジネス寄りの内容です。
参加してみると、AIというよくわからない言葉をわからないままにせず、出来ること、出来ていないことを分析した上で、開発やビジネスでどのように取り組むのか、そのノウハウまで教えてもらえたので、開発・ビジネス、マネージャ・メンバーなど職種やポジション関係なく、AIにこれから取り組む方にはオススメの内容でした!!
(AIにありがちな夢物語や恐怖物語はまったく出てきません)
それではどのような内容だったのか、レポートします。
もくじ
コース情報
| 想定している受講者 | AIについて知り、ビジネスへの活用に踏み出せる入り口を目指します |
| 受講目標 |
|
講師紹介
参加してみたレポートでも、今期のSEカレッジでも初登壇の 鈴木 健男さん です。
アカデミックな雰囲気をお持ちで、とてもソフトなお話ぶりだったので、はじめこそ学校の授業のようになるのかな、と思いましたが、AIに関して疑問に思うこと、謎めいたことをどんどん鈴木さんが明かしていくにつれ、興味関心がグイグイ引き寄せられました!
なぜ、私が漠然と謎に思っていたことがわかったのでしょう w
AIはこわい?

- 雇用は奪われる? シンギュラリティ (AIが人を超える) とか
- 今の時点では人間をサポートするもの
このコースでわかれば、こわくなくなる、ということですね。
そこで鈴木さんからはこの “AI” という言葉がとても曖昧なので、
- AIをさまざまに整理・分類する
- ビジネスに活用できていること (実はまだ狭い)
これがこのコースの狙いと紹介いただきました。
AIとは?
そもそもAIとは
- 機械に知能を与えるという理解
- 感情まで含めて知能という学者もいる
- ビジネス上でAIと言っていることもある (AIではないこともある)
- AIはソフトウェアプログラム
- 何かを学習して、その結果を出す
- 分類結果であったり、認識・認知結果であったり、予測を出したり
- 何かを学習して、その結果を出す
- 例えば画像処理の場合
- 何の花なのか判定する
- 美しいかどうか判定する
- コンピュータそのものでは判断できず人間の判定結果を学習させると判定できる
- いつまで咲いているか判定する
AIもプログラムと言わると急に安心感が出てくるのは気のせいでしょうか。インプットがあって、それを処理するプログラムがあって、なんらかのアウトプットがあると考えれば、色々と見方が変わりますね。
モラベックのパラドックス
ただ、そこで紹介されたのが、モラベックのパラドックスというものでした。

この “不可能” を超えられるかどうかがシンギュラリティへの壁と言われているとのことでした。
むむ、確かに何の学習もない状態から出来るようになると、それは人間ですね。この用語に関する論文が出たら要チェックです。
AI の分類
さて、ここからはAIを色々と分類していきます。不思議なもので、様々な観点で分類されると、曖昧模糊としたものから輪郭が形作られるような感覚がありました。
特化型AIと汎用型AI
- 特化型: 車や自動運転など特化した適用範囲がある
- いくつかのモジュールで実現している
- 認識モジュールと制御モジュールと予測モジュール
- 代表的なもの AlphaGo
- 汎用型: 人間らしさ
- AGI (Gはgeneral)
- 全脳アーキテクチャ
- シンギュラリティ
関連した言葉で 強いAIと弱いAI という分類も紹介されました。強いAIは心を持つかどうかとされていて、いま国内で基準を作ろうとしているということでした。
私の個人的な見解は、以前に AIベンチャーの雄が総務省の開発指針に反対する理由 という記事があり、この記事の見解同様にまだそんな基準は先で良い派です。
ルールベースと機械学習
- ルールベース
- チャットボットでよく使われている
- QAのパターンを作っておいて、9割ぐらいの正答率でもよい場合に使われている
- ただ、ルールが膨大だと大変。。
- 関連して “巡回セールスマン問題” という問題があり、研究分野の一つにもなっている
- 実はあんまり普通のプログラムと変わらない
- 局所的には機械学習を使っている
- ex.この名前は個人の名前なのか会社名なのか
- 機械学習
- 学習するためのシステム、学習器を作って学習モデルを生成する
- 学習器:データ (訓練データ) を学習する仕組み
- 膨大なデータに対応できる
- なんでそうなったかはわからない。。
- 学習するためのシステム、学習器を作って学習モデルを生成する
人工知能レベル
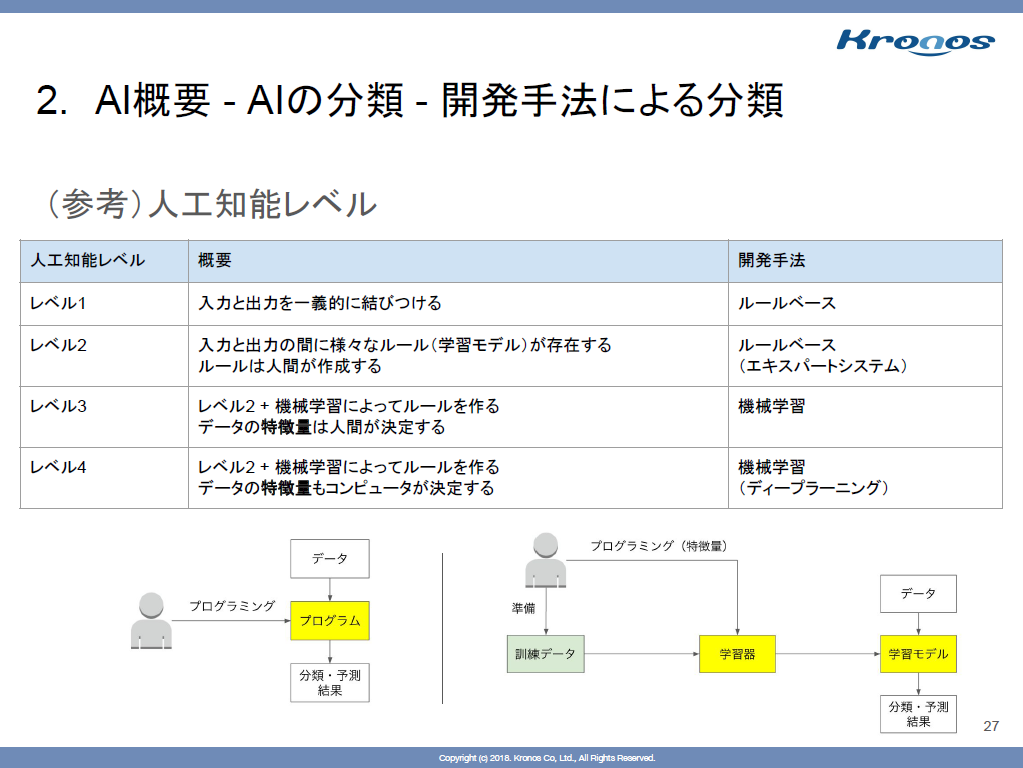
関連して、上のスレイドでレベルを紹介頂いたのですが、とてもわかりやすいレベルですね。ちなみに、エキスパートシステム、という言葉は 「白夜行」(東野圭吾 著 集英社刊) でも出てきたので、一人じんわりしてました。
第1次AIブームと第2次AIブームと第3次AIブーム
- 第1次 ゲームの攻略だけを目的とした時代
- 1950年代 ~ 1960年代
- 第2次 匠と呼ばれるようなエキスパートをプログラム化すれば良いのでは、というアイデア
- 1980年代
- 専門家やエキスパートの知識や感覚が膨大でかつ暗黙知があったのでダメだった
- 第3次 深層学習で “どう学習するか” が出来れば、AIができた
- 2010年ごろから
- Googleの猫と呼ばれ、深層学習で猫の写真を大量に学習させると、猫と認識する論文が突如発表された
GoogleはHadoopでもそうでしたが、突如として論文発表するのが好きですね。ちなみにGoogleが発表した論文は Publications – Google AI で公開されているのですが、もともと Google Research というページタイトルだったので、研究もAIにシフトしているようです。
AIの仕組み
AIの輪郭がつかめたところで、どういう技術・仕組みで、どう作るのか、という話に移ります。
なぜAIが発展したのか?
- データが集まる環境ができたこと
- SNSなど
- twitterなどは自然言語処理でよく使われる
- データを活用する仕組みができたこと
- ディープラーニングは昔からあったんだけど、リソースが厳しかった
- いまはGPUとクラウドで調達できるようになった
- とはいえGPUですら学習モデルを作るのに1週間掛かったりすることもある
AI にできること
- 2015 認識の向上
- 2020 行動技術の向上
- 2025 対話技術の向上
- 総務省が 2014年9月に発表した 人工知能の未来 (松尾豊 准教授 [発表当時])
- 思ったより早いので1年ちょっとで2回バージョンアップ (マジ!?)
バージョンアップしたもの
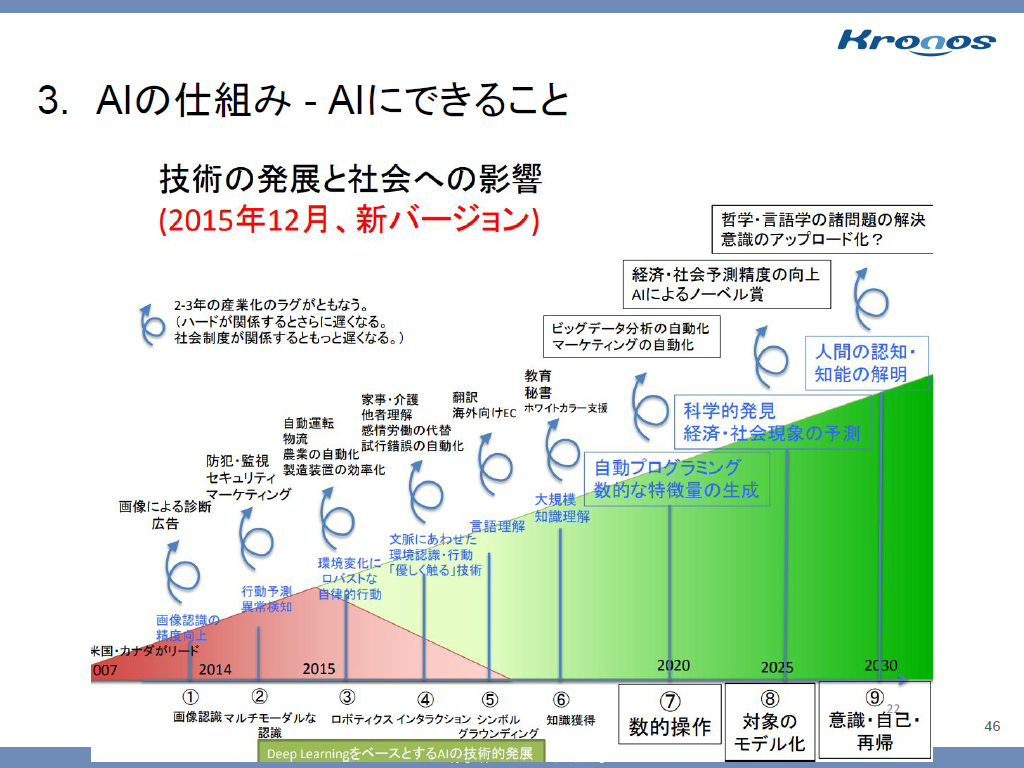
- ちなみに第2次AIブームのエキスパートシステム “レンズ磨き職人” の技を深層学習でやり始めたら精度がでて商用化
- FANUC + Preferred Networks が実現
機械学習
- 教師あり学習と教師なし学習
- 教師あり学習
- 訓練データと認識させたいことをセットで学習させる
- テストデータをもって正答率をチェックし学習精度を上げる
- 訓練データに最適化しすぎて、テストデータの精度が落ちる場合がある (過学習という)
- 学習してないことは理解できない
- 分類 (迷惑メールフィルタリングや検品) や 回帰 (売上予測など予測など) で使われる
- 教師なし学習
- データの特徴を学習し、分類する
- クラスタリングで使われる
- 教師あり学習の前にやったりする
- 3万件の学習データを人力で仕分けるとかやってられない…
- 一杯ある画像から人の画像出して、みたいなやり方
- 教師あり学習
- 学習フェーズと判定フェーズ
- 学習フェーズ: 学習器に訓練データを学習させる
- めっちゃリソース食います
- 判定フェーズ: 学習モデルから未知のデータで判定する
- 学習フェーズ: 学習器に訓練データを学習させる
- 一度作った学習モデルは一般的に他システムから Web API のように使えるようにします
AIのつくり方
- AIサービスを活用する方法
- 例えば Watson や Google Cloud ML や Amazon AI など
- すでに学習モデルが出来ているので、リクエストを投げるとレスポンスがある
- 導入そのものは安価ですぐに利用可能
- 1リクエスト課金なのでスグに試せても運用するとコストが高い…
- 自社でAI (学習モデル) を作る
- TensorFlowやKeras、Chainer などのフレームワークを使って学習器と学習モデルを作る
- パラメータとか設定できるけど、エンジニアが入らないと開発できない
- 1000万円~2000万円かかります。。
- データも用意してね
- AmazonMLやMicrosoftAzureMLを使う
- 学習器と学習モデルが用意されていて、訓練データは自社のものを使って出す
- 自社開発よりは安い
- 訓練データのラベリングやフィルタリングをやってくれるベンダーがいる
伺えば伺うほど、学習モデルを作るには膨大なデータと、膨大なコンピュータリソースが必要なので、Google無双なのではと思ってしまいます。そんな中、Chainer が国際的にも認められて、かつトップカンファレンスでも実績も出てきているので、本当にPFNはすごいところです。。
- ODSC East 2018で、Chainerが Open Source Data Science Project賞を受賞 // 過去にはPandasやScikit-learnが受賞
- Preferred Networks、深層学習の学習速度において世界最速を実現
いまのAI 活用
技術がわかったところで、どのようにビジネスに活用するのか、というお話です。
活用事例の紹介
- チャットボットまなみさん
- Microsoft Pixカメラ
- 無料
- 横書き名刺なら精度高め (縦書き名刺はNG)
- ローン審査
AI開発方法の検討
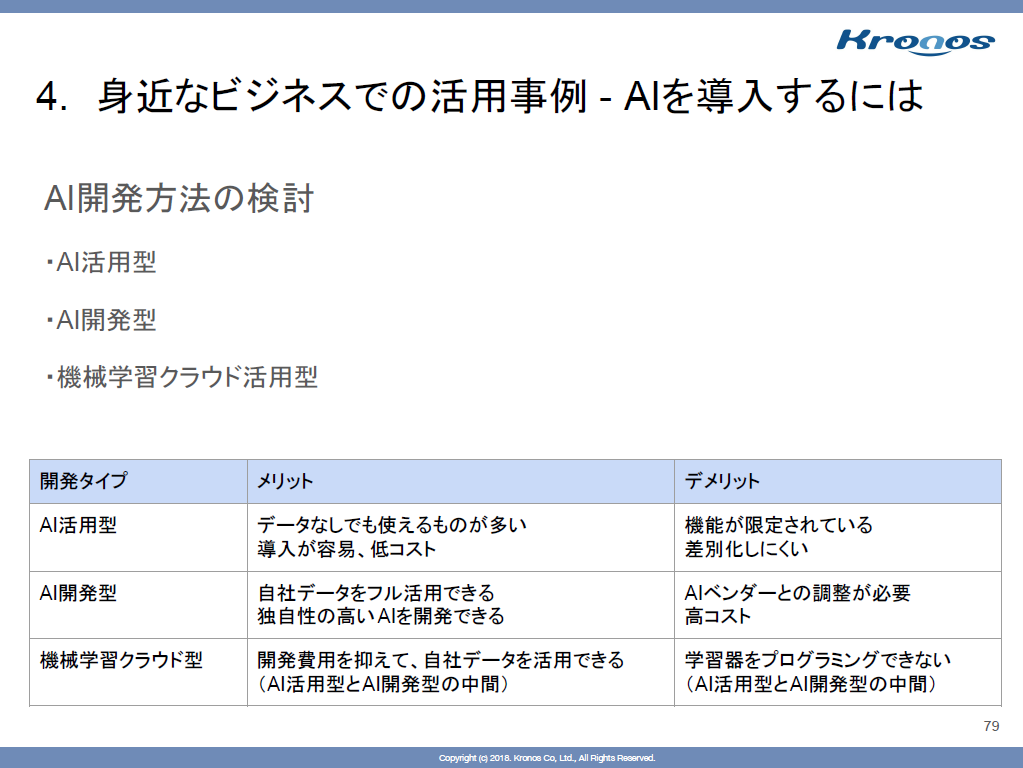
- 1回では開発終わりません。。
- まずはプロトタイプを作って、AI開発型に発展していくとよいです
- 注意したいのはAI開発ベンダーは学習器と学習モデルを開発するまでで、webアプリに組み込むまではやらないことが多い
- 契約も重要
- 精度 % 以上のような契約? 1回の検証でいくら? という契約が多い
- ちなみに精度100%はない
- 開発プロセスも重要
- 繰り返しやるのでウォーターフォールにならない
なかなか従来型の契約形態では難しそうです。鈴木さんに個別に質問すると、成果の判定も難しいので研究開発費でまるっと計上することもあるそうです。
これからのAI
そして最後に、AIの未来を紹介いただきました。
(再掲)
- 2020 行動技術の向上
- 2025 対話技術の向上
注目の技術
- 強化学習
- 特定の環境でランダムな動作をしながら、報酬を最大限にする訓練のやり方
私も気になったので強化学習をコース参加後、調べたのですが、下の記事が例えを交え、とてもわかりやすくまとめられていました。
AIに出来ないこと

ここでコースは修了となりましたが、修了後、鈴木さんにスキルアップについて質問すると、とても参考になったので、まとめておきます。
エンジニアのAI対応
- APIを使うだけなら今のままでOK
- AI開発を行う人でもレイヤーがある
- AzureML、AmazonML を使うだけ
- アルゴリズムを知っておくとよいでしょう
- オリジナルな特化型の学習モデルを開発する
- 数学もPythonもフレームワークなど色々必要
- フレームワーク: TensorFlowやKerasやChainerなど
- AzureML、AmazonML を使うだけ
まとめ
AIの過去~現在を中心に様々に分類を行い、輪郭を掴んだ上で、仕組み (技術) と未来を学びました。
特にAIの開発では開発目標、開発範囲、契約内容など自社で経験されたことをノウハウとして教えていただき、メモする方がとても多いのが印象的でした!
体系化された、学びやすい順路でしたので、職種、キャリアに関わらず、これからAIに取り組もうとする方にはとてもオススメです!
label SE カレッジの無料見学、資料請求などお問い合わせはこちらから!!
label SEカレッジを詳しく知りたいという方はこちらから !!
SEプラスにしかないコンテンツや、研修サービスの運営情報を発信しています。