Kaggle で学ぶ!機械学習 モデル 開発入門|研修コースに参加してみた

今回参加したコースは Kaggle で学ぶ!機械学習 モデル 開発入門 です。
先日レポートした「ノーコード( NoCode )で体験する AI 開発のキホン」のように、機械学習の環境やツールが整備されて、専門家でなくても簡単なモデルを作成できるようになってきました。
さらにもう少し学んで知識を深めたいとなったときに、解くべき問題や、その成果物に対する評価があると励みになりますよね。
そこで、 Kaggle という機械学習のコンペのサイトを使うと、問題やデータセットと評価、そして機械学習を実行する実行環境が一式用意されます。専門家から入門者まで、世界中からデータサイエンティストが集まる人気サイトです。
このコースでは、機械学習の概要の知識はわかっているものの、実際に自分でモデルを作成したことがない方を対象に、 Kaggle の使い方や、 Python による機械学習のコードの書き方などを学んで… ナント、 Kaggle デビューできました!!!
では、どのような内容だったのかレポートします!
もくじ
コース情報
| 想定している受講者 |
|
|---|---|
| 受講目標 |
|
講師紹介
「ノーコード( NoCode )で体験する AI 開発のキホン」につづき、 井上 研一 さんが登壇されました。

今日のコースのアジェンダを紹介いただき、実際に Kaggle のタイタニックというコンペに参加して、実際に作ったモデルを出してみましょう、とお話いただけました。
Kaggle デビュー … できるのでしょうか。ワクワクしますね。
データ分析の進め方
まずはモデルの開発の前段階、データ分析について解説いただきました。
- モデルを作る前に、事前にデータの特徴を掴む = データ分析
では、どのようにデータ分析を進めるのでしょうか。
- ビジネス課題の理解 Business Understanding
- As-Is (現状) と To-Be (将来のあるべき姿) のギャップが課題
- データがあるからやるのではない
- データの理解と収集 Data Understanding
- 必要なデータを仮説を立てて集める
- 扱いやすいデータに整形する (前処理) Data Preparation
- 様々なデータを 1 つにまとめる
- 雑多な非構造化データを構造化する
- 外れ値や欠損値などを補完
- データ分析 Modeling
- アクション Evaluation & Deploy
- ギャップが埋められたかどうかを Validate
- ギャップが埋められなければ、やり直し
Kaggle とは
Google に買収されたことで一気に有名になった Kaggle について紹介いただきました。
- 企業や研究者がデータと賞金とお題を設定したコンペを開催し、世界中のデータサイエンティストが参加
- 実際にスコアが良かったデータサイエンティストが表彰され、賞金獲得ができる
よく記事でもトップランカーの Kaggler が在籍しているという企業 PR を見るようになりました。
- Kaggle のコンペの概要
- 訓練データとテストデータが提供される
- テストデータをモデルに入れて予測や分類をする → この結果で競う
- Kaggle 内にも Python を動かせる環境がある
今日はその Kaggle のコンペの中でも「タイタニック」という、初心者向けのチュートリアルのようなコンペに参加します。ドキドキ。
NoteBook を使って Python の肩慣らし
ここからは実際、 Kaggle でアカウントを作成・ログインして、サイト上に用意された環境 ( Notebook ) で演習します。
まずはその Notebook で Python でプログラミングの肩慣らしのため、定番の FizzBuzz 問題に取り組んでみます。
- FizzBuzz 問題とは
- 1 ~ 100 までの数字で以下の条件で出力
- 3 で割り切れれば「 Fizz! 」
- 5 で割り切れれば「 Buzz! 」
- 3 と 5 で割り切れれば「 Fizz Buzz! 」
- 上記以外の場合は、そのまま数字
- 1 ~ 100 までの数字で以下の条件で出力
研修中は井上さんから Gist ( GitHub が開発したコードスニペットを共有できるサービス) を使って、事前に用意されたサンプルコードを共有いただいたので、スムーズに作業を進められました。
for i in range(1, 101):
if i % 3 == 0 and i % 5 == 0:
print('Fizz Buzz!')
elif i % 3 == 0:
print('Fizz!')
elif i % 5 == 0:
print('Buzz!')
else:
print(i)コンペ「タイタニック」でデータ分析
では、実際に「タイタニック」に参加します!
タイタニックは、あのタイタニック号の乗客データを元に、生存者を予測するというコンペです。
画面でトレーニングデータとテストデータ、最後にコンペに Submission (提出) するデータを確かめた上で、井上さんから、統計の基本や質的データ・量的データを解説いただきました。
Pandas によるデータの可視化と前処理
Python のライブラリの Pandas を使って、トレーニングデータを分析します。
- データセットを読み込む
- カラム情報などを取得
- 列名からデータを全件取得
- index を使ってデータを取得
- グルーピングして統計的な処理をやってみる
- 等級ごとの運賃の平均を出してみる
- 基本統計量を出す
- 欠損値の探索と削除
- 欠損値を補完する
井上さんのサンプルコードをコピペしながら進められるため、データの見方や出力されたデータの分析の解説に集中できます。
matplotlib と seaborn で可視化
つづいて、データをグラフなどで可視化してみます。可視化するとデータの全貌が直感的にわかりますね。
- matplotlib と seaborn を import
- チケットと生存の関係を見てみる
- 年齢と生存を見てみよう
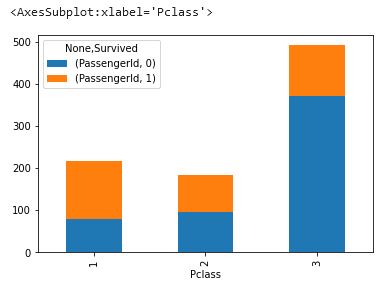
データ分析していると、
- 1 等に生存が多い
- 性別でも特徴がある
- 子どもは生存している確率が高い
などがわかってきました!
このあと、
- seaborn を使ってカラムの相関を可視化
- scikit-learn を使ってデータ分割
- モデルを評価
- 精度改善
こういった取り組みをして、モデルが完成しました!!
Kaggle デビュー
モデルができたので、いよいよ Kaggle で提出してみます! (ドキドキ)
- テストデータをモデルに入れる
- デフォルトで用意されいた提出用データを上書き
- 画面からその提出用データを提出する
この結果、画面でスコアと順位が表示されました!!
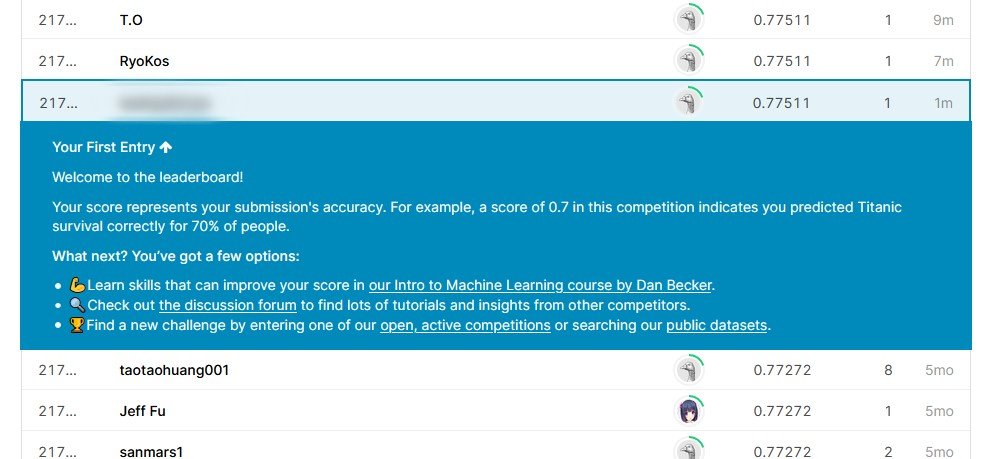
もう順位が省略されてしまって、何位なのかわからないぐらい(笑)ですが、 Kaggle デビューできました!!!
デビューできたところで、このコースは修了しました。
まとめ
Kaggle の初心者用コンペを使って、データ分析からモデル開発までの一通りのステップを Python のライブラリを駆使して体験できました。
コース参加前はハードル高めだと思っていましたが、井上さんのサンプルコードやスムーズな手順で楽しくモデル開発ができました。
また、「ノーコード( NoCode )で体験する AI 開発のキホン」を受講していたので、 GUI で操作したステップと今回 Python のライブラリで行ったステップが、ほぼ同じだったことに気づき、モデル開発の流れを追体験できました! そして、 Kaggle デビューもできました!! いえい、いえい!!
AI に興味をもって、 Python での機械学習を持っている方にはとてもオススメの入門コースです! そして Kaggle デビューしましょう!!
label SEカレッジを詳しく知りたいという方はこちらから !!
IT専門の定額制研修 月額28,000円 ~/ 1社 で IT研修 制度を導入できます。
年間 670 コースをほぼ毎日開催中!!
SEプラスにしかないコンテンツや、研修サービスの運営情報を発信しています。