AutoML による機械学習の変化|研修コースに参加してみた

今回参加したコースは AutoML による機械学習の変化 です。
「 AI の民主化」 という言葉をご存知でしょうか? AI を使うハードルが下がり、使いやすくなるというものです。 GPT シリーズがその典型ですね。
このコースでは、機械学習の一連のプロセス、前処理 ~ モデル作成を定番の Pandas や scikit-learn をやってみた上で、 AI の民主化の一つ、 AutoML を使ってモデル作成を自動化してみました! 結果、な、なんと一行のコードでアルゴリズム比較が終わるなど、自動でいい感じになりました … 。
では、どのような内容だったのか、レポートします!
もくじ
コース情報
| 想定している受講者 |
|
|---|---|
| 受講目標 |
|
講師紹介
AI に関する書籍を多数執筆し、 SE カレッジでも AI の分野で多く登壇される 井上 研一 さんが講師でした。
2000 年よりプログラマ・ SE として企業の業務システム開発に従事し、 2012 年に独立。 AI や IoT に強い IT コーディネータとして活動中。
北九州市主催のビジネスコンテスト「北九州で IoT 」に応募したアイディアが入選。メンバーと株式会社ビビンコを創業。 著書に「初めての Watson 」、「ワトソンで体感する人工知能」など。セミナーや研修講師での登壇も多数。
今回やることを簡単に紹介いただきました。
- Pandas で前処理
- scikit-learn でモデル作成
- PyCaret で自動モデル作成
- デプロイ
PyCaret は AutoML という分野で注目されているライブラリで、冒頭でも触れた AutoML は機械学習のアルゴリズムの選択、パラメータのチューニングなどを自動化するものと井上さんに補足いただきました。
データセットと開発環境
機械学習のコースではおなじみの Google Colaboratory を使用してコードを実行します。
今回も井上さんは予め Gist にたくさんのサンプルコードを用意されていて、実習時にはそれをコピペすれば動きました。 井上さんのコースでは毎度ながらの風景ですが、これを用意するのはとても工数が掛かるので、本当に頭が下がります。
このレポートでは、コードや資料は受講してのお楽しみ、ということで、簡単に手順などを紹介します。
なお、使用するデータセットは以下です。
- Dataset UCI からダウンロードできる Automobile Data Set
- この中の imports-85.data を使用
- 自動車のスペック情報をまとめたもの
requests というライブラリを使って、早速データセットをダウンロードします。
このあと、データセットをざっと説明いただき、簡単に構造化データ / 非構造化データの違い、量的データ / 質的データの違いを紹介いただきました。
定番ライブラリによる前処理 ~ モデル作成
Pandas による前処理
準備が整ったところで、本日の開発のお題です。
自動車のスペック情報から価格を予測する
まずはモデル作成の前の工程となる前処理を Pandas で行います。
-
Pandas とは
- 構造化データを扱いやすくする
- 井上さん曰く、 Python の Excel というイメージ
Pandas でよく使う DataFrame を使って前処理を進めます。
- DataFrame にしてデータを読み込み確認
- データの形状 / 列名の取得
- 列名を指定してデータの取得 / 条件を指定したデータの取得 など
- 基本統計量を出力 :
describe()を使用describe()で価格 price が表示されないので、型を調査- 価格に欠損値 ? NaN があるためオブジェクトになっている( int になっていない)
- ? を置換して型変換: NumPy を使用
- 価格 price も
describe()で出力できるようになる
- 価格 price も
- 幅、長さ、価格など数値で表せるデータ(量的データ)と、メーカー名など数値ではないデータ(質的データ)を確認
- 欠損値の確認 :
isnull()を使用- 欠損値があると、モデルが作れないアルゴリズムもあるので、欠損値が無い方が良い
- 欠損値を処理する
- 2 つのやり方がある
- 欠損値のある行を削除 :
dropna()を使用- データ量が少なくなってしまう
- 欠損値を補完するというやり方もある :
fillna()を使用- 中央値などを使って当たり障りのない値にする
- 欠損値のある行を削除 :
- 2 つのやり方がある
井上さんが手順をまとめてくれているのでスムーズに進みましたが、自分で前処理することをを考えると、いちいちデータを確認しなくてはならないので、とっても面倒そうです … 。
なお、 Pandas や NumPy などのライブラリは他のコースでも触れていますので、ぜひこちらもご覧ください。
info_outlinePython の機械学習ライブラリ

データの可視化と分析
データの前処理が終わったところで、今度はデータ分析を進めます。
- matplotlib と seaborn を使って可視化
- 相関を調べる
corr()で相関係数で一つ一つの列を比べる- 一つ一つだと面倒なので相関行列を使う : DataFrame 全体に
corr()できる- ヒートマップで出力すると見やすい
- 散布図行列を使うと、強い相関がある項目がわかる
- カテゴリ変数( 0: toyota, 1: nissan などの質的データ)は意味のない計算をしてしまうので変更
- ダミー変数にする:
get_dummies()を使用- メーカー名の列を作成し、行ごとに 0, 1 をつける
- 列が増え、計算量が増えてしまう
- ラベルエンコーディング :
LabelEncoder()を使用- メーカーごとに数値を割り当てるので計算量が増えない
- 数値にするので大小関係が出てしまう
- ダミー変数にする:
最後に、上記の手順で加工した DataFrame を csv として保存し、あとで使用できるようにしました。
scikit-learn によるモデル作成
データの相関を分析できたところで、 scikit-learn で学習モデルを作ってみましょう。
- scikit-learn はたくさんのアルゴリズムが使え、とっかえひっかえできる
- 今回は教師あり学習で回帰モデルをつくる
- 量的データで予測
- ちなみに質的データなら分類モデル
まずはデータを分けます。
- 目的変数と説明変数にわける
- 今回は目的変数が price で、説明変数はそのほかの列
- 訓練データとテストデータにわける :
train_test_split()を使う- 今回は 8 割を訓練データにする
では、実際にモデルを作成してみましょう。 せっかくなので複数のアルゴリズムを使って、精度を見てみます。
- モデルを作成
- scikit-learn のチートシートでアルゴリズムを決めるのも一つの手
- 線形回帰を試してみる:
LinearRegression()を使用 - 決定木を試してみる :
DecisionTreeRegressor()を使用 - ランダムフォレストを試してみる :
RandomForestRegressor()を使用- たくさんの決定木を使って、平均値をとる
- 引数に決定木の量を決める
- 勾配ブースティング木を試してみる
- 決定木の一種で、決定木を次々作って、誤差を小さくしていく
- 今回は
XGBRegressor()を使う( scikit-learn にはない)
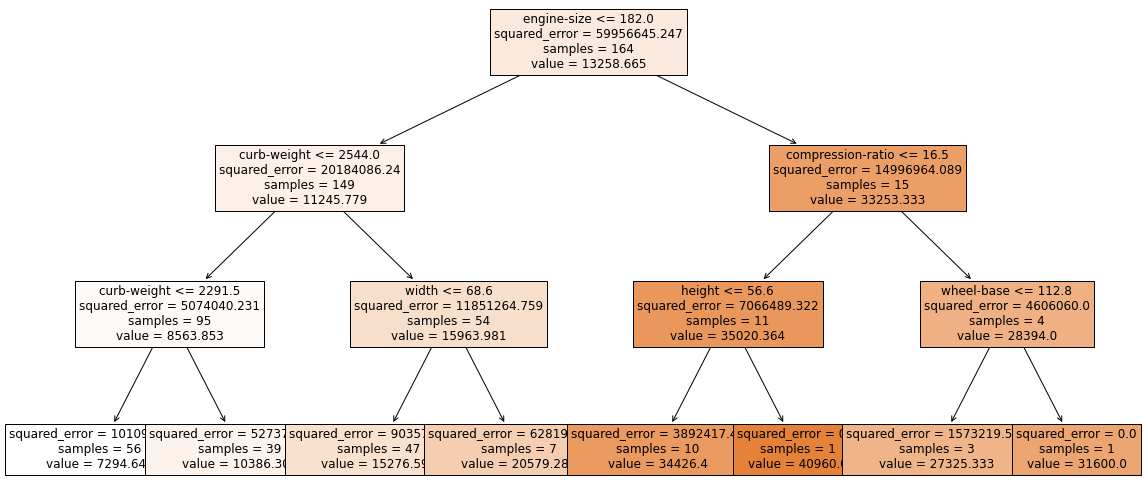
- モデルを評価 :
score()とテストデータを使う- 線形回帰は 0.69
- 決定木は 0.63
- ランダムフォレストは 0.67
- 勾配ブースティングは 0.649
- 実際にテストデータから 1 行使って予測してみる :
predict()を使う
ただ単にアルゴリズムを適用しただけの初期作成なので、普通はこのあとチューニングを行い、精度を上げます。 ここでは時間の関係ではできないため、なかなか思ったような精度は出ていませんね。
また、このあとに続く話として、 scikit-learn では一つ一つアルゴリズムを試していることをご記憶ください。
AutoML の代表格 PyCaret で自動モデル作成
ここまで定番のライブラリを使ってモデルを作成してきました。 ふりかえりとして、これまでの問題点を整理します。
- 精度の評価は未知のデータの精度できまる
- 交差検証法も検討してみよう(先ほどの
train_test_split()はホールドアウト法)
- 交差検証法も検討してみよう(先ほどの
- さらに精度を上げるには?
- 訓練データ or 学習器 を改善する
- 学習器は PyCaret である程度、自動で精度を上げられる
- 訓練データ or 学習器 を改善する
- 現在はアルゴリズムの選択やパラメータの調整より、 データの量と質のほうが重要 になっている
では、その PyCaret でどのようなことができるのでしょうか。
-
PyCaret とは
- OSS で Python のローコードツール
- AutoML と呼ばれ、自動で複数のアルゴリズムでトレーニング/評価し、チューニングも自動で行う
- scikit-learn や XGBoost などの機械学習ライブラリをラップしたもの
scikit-learn で 1 回 1 回試して精度を評価していましたが、 PyCaret ならすべて自動でやってくれます(ナント!)。
では、 PyCaret を使ってみましょう!
- データの読み込みとデータの分割 -> データをセットアップ :
set_up()- このコースでは使わなかったが、引数を指定して簡単な前処理も自動化可能
- アルゴリズムを比較 :
compare_models()- 今回は knn (KNeighborsRegressor K−近傍法) がよいという判断
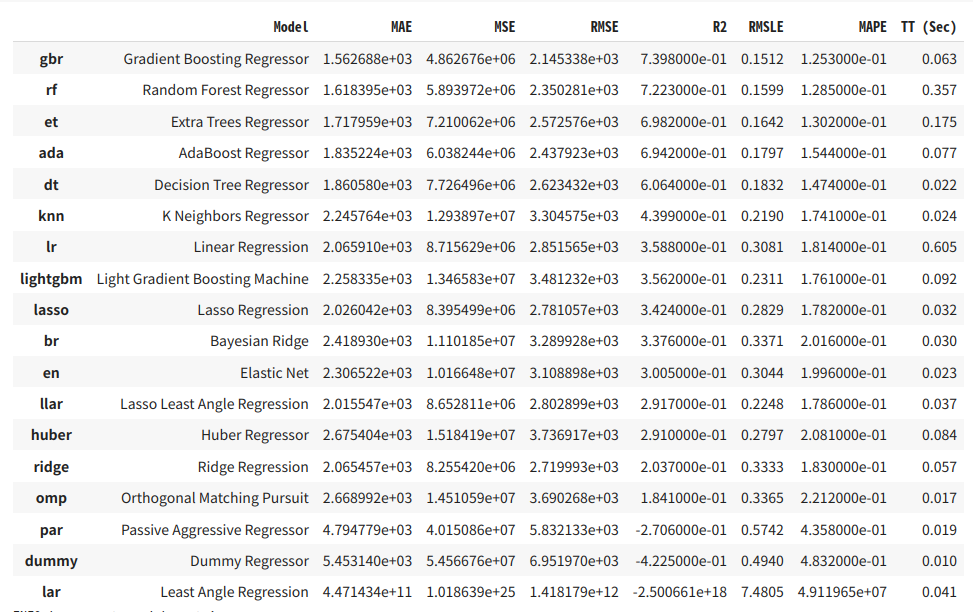
上記は筆者の環境。 スコアはランダムで変わるときがあるため、 knn がよいという結果ではありません
- 今回は knn (KNeighborsRegressor K−近傍法) がよいという判断
- モデルを一旦パラメータチューニングなしに KNeighborsRegressor で作成 :
create_model('knn')- データの分割も自動で交差検証法を使っていた
- ハイパーパラメータを実施(これも自動) :
tune_model()- ハイパーパラメータ: 人間が設定するパラメータ
- モデルを評価 :
evaluate_model()- Residuals (予測値との残差。 残差 0 で横に並んでいると良い)で確認
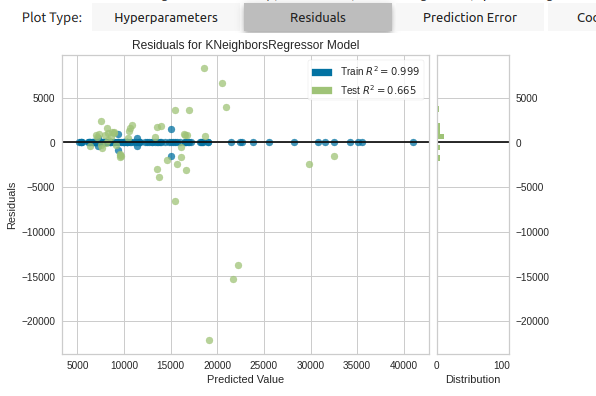
- Residuals (予測値との残差。 残差 0 で横に並んでいると良い)で確認
- モデルを最終作成 :
finalize_model() - モデルの精度評価 :
predict_model() - モデルを保存 :
save_model()-> 予測を行う
モデルを保存すると、 pkl ファイル( Python のバイナリファイル)ができ、 load_model() で学習モデルの呼び出しができます。
それにしても、アルゴリズムの比較を、たった一行でやっていて、ラクすぎました。 その他にも、ほとんどの処理を一行で完結していて、まさしくローコードですね。
モデルをデプロイ
最後に作ったモデルをデプロイして、 API のように使ってみましょう。
Colaboratory で 2 つのノートブックを動作させて実行させる、特殊なやりかたなので、井上さんのデモを見ました。
- API サーバをつくる
- 今回は Python のフレームワーク Flask を使用
- フルスタックの Django より、とっても軽量
load_model()で先程作ったモデルを呼び出す
- 今回は Python のフレームワーク Flask を使用
- 別のノートブック(別サーバを立てるようなもの)から API を叩くので URL が必要
- ngrok というサービスで URL を発行し、 Colaboratory 上の Flask とポートフォワーディング
最後に新しいノートブックを作って、リクエストする JSON を ngrok で作った URL に POST すると、無事に予測価格が出力されました。
この出力結果を確認したところで、このコースは修了しました。
まとめ
機械学習の定番ライブラリ、 Pandas と scikit-learn を使ってデータの前処理からモデルの作成をした上で、 AutoML の代表格である PyCaret を使ったモデル作成の自動化を行い、実際に利用するところまで体験しました。
PyCaret を使ってみると、井上さんがおっしゃる通り、データの量と質、つまり前処理の前のデータ収集や分析という作業が重要になっていることを肌で感じました(調べてみると、 PyCaret で欠損値処理、カテゴリ変数の変更などの簡単な前処理も自動でできます)。 GPT-4 が一般的になってもこの作業はできませんので、より一層重要ですね。
数年前の参加レポートでは考えられないぐらい、 AI が着実に進化し開発者フレンドリー、ユーザフレンドリーになっている、 いわゆる「 AI の民主化」を実感できるコースでした! これから AI 開発を始める、という方にもオススメです !!
label SEカレッジを詳しく知りたいという方はこちらから !!
IT専門の定額制研修 月額28,000円 ~/ 1社 で IT研修 制度を導入できます。
年間 670 コースをほぼ毎日開催中!!
SEプラスにしかないコンテンツや、研修サービスの運営情報を発信しています。