NoSQL 入門 ~ RDB の限界と NoSQL データベースの種類|研修コースに参加してみた

今回参加したコースは NoSQL 入門 ~ RDB の限界と NoSQL データベースの種類 です。
NoSQL という言葉の登場以来、 10 年以上が過ぎ、ベストプラクティスが見え、成熟化しました。一方で、 GAFA など一部の巨大サービス企業で使われるものという認識も変わり、一般的なサービスでもデータストアに RDB だけでなく様々な NoSQL データベースを利用することが増えました。
このコースでは改めて、その RDB では難しかったことを Twitter をサンプルとして考え、 NoSQL で出来ることや、数多くの NoSQL データベースの特徴や SQL との違いが学びました。
なお、このレポートはいつもの講座 / リアルタイム配信のスタイルではなく、動画契約企業がいつでも視聴できる「いつでも動画」に収録されている、「 NoSQL とは何か? (1) 」「 NoSQL とは何か? (2) 」の 2 コースをまとめたものです。動画では、1 コース 1 時間程度で、トピックごとに分けられた短い動画を見て学習できます。分かりにくかったところや聞き逃したところなどを繰り返し再生できるのが便利ですね。
では、どのような内容だったのか、レポートします!
もくじ
コース情報
| 想定している受講者 | SQL を学習済であることが望ましい |
|---|---|
| 受講目標 |
|
講師紹介
講師は AI / IoT だけでなく JS 、 DB など幅広い分野で登壇される 植田崇靖 さんです。

植田さんのコースは以前にも他のコースでレポートしていますので、ぜひご覧ください。
機械学習 モデル の作り方と必要な基礎知識|研修コースに参加してみた
JavaScript 練習 ドリル 研修コースに参加してみた
NoSQL とは
まず NoSQL の概要を紹介いただきました。
- 諸説あるが、 Not Only SQL の略と言われている
- RDBMS 以外という大きな括り
- ただし NoSQL の中には SQL が使えるものもある
- ビッグデータとともに注目されている
NoSQL が使われるようになった背景には、 3 つの V があります。
- Volume:データ量の増加
- 従来の DB は大きくても限られていた
- Twitter は 1 日に 10 TB
- 分散 DB になった
- Velocity:処理速度の増加
- たとえば 12 TB を格納しようとしたとき、転送速度を考えると、 1 日では足りない
- 複数台で同時並行で処理
- Variety:多様性の増加
- 既存の DB に格納されるのは、数値と文字列ぐらい
- SNS のように画像や動画など、いままで扱わなかったデータをストアする必要がある
- 構造を持っていないデータ、あるいは JSON のような半構造データを格納
RDB の限界
RDB が既に使われているところでは無くなることはないが、限界も見えてきているとのことでした。
- 大量データ
- 1 PB のデータを格納するには 1 TB の HDD が 1000 個必要
- 処理速度:毎秒数万件のクエリを 1 つのハードウェアで処理するのは無理
- スケールアウトによる分散処理の必要
- RDB ではあまり得意ではない
- 半構造データ
- 構造はあってもスキーマがない
- RDB では納めきれない
- 例えるなら、データを 1 つのセルにたくさん入れなくてはいけない
- RDB のメリットが生かせない、向いていない
- 構造はあってもスキーマがない
RDB の限界
たとえば、 Twitter API を使ってツイートを RDB にストアして、好きな属性で検索できるようにしたい場合には、次のような問題があります。
- 約 90 のキーと値のペア
- テーブル設計が困難
- 動画も写真もある
- キーの名前もひんぱんに変わる
- 列の定義が難しい
- 列名も、そのデータ型も変わる
- パフォーマンスがでない
- API の変更
RDB では無理ゲーですね … 。
そこで Twitter の API から取得できるデータは JSON なので、それが得意な “ドキュメント DB ( NoSQL )” を使うと良さそうです。
- JSON のデータをそのまま格納できる
- JSON のデータからキーで絞り込める
- 負荷によるスケールアウトができる
- データ構造が変わっていても JSON をそのまま格納しているのでデータロスの危険性がない
NoSQL のよくある勘違い
一方で、 NoSQL にはよく勘違いされているケースがあるとのことでした。
- バッチは高速にはならない
- バッチ処理をするものは基本的にない
- トランザクションが高速にはならない
- トランザクションは ACID 特性を担保にしている
- NoSQL の多くは ACID 特性をトレードオフにして、スケールアウト (並列処理) を志向している
- ビッグデータの分析に特化しているものばかりではない
- 分析機能に特化したものは少ない
- RDB から置き換えると必ずしも処理が速くなるとは限らない
- 置き換えるものではなく、新しいものを追加するという考え方がよい
- 「オープンソースしかない」は誤り
- 商用プロダクトも商用ライセンスもある
- 「スキーマがない」は誤り
- スキーマがないわけではない
- SQL が使えないは誤り
- Cassandra は SQL に似た CQL を使う
NoSQL データベースの特徴
NoSQL はただの括りなので、さまざまな種類のデータベースが含まれます。一概には言えませんが、大枠で次のように分けられます。
- KVS (キーバリューストア)
- ドキュメント DB
- グラフ DB
- etc.
KVS
ここからそれぞれの NoSQL データベースの特徴を見ていきます。
まずは KVS の特徴です。
- 短いターンアラウンドタイムで応答できる
- データ構造
- キーバリューストア
- キーに対して値が 1 つ
- ワイドカラムストア
- キーに対して複数の値を格納できる
- 複数の値が必ず入っている必要はない
- この 2 つでどのソフトかが変わるので注意
- キーバリューストア
- データ間は疎結合
- 結合が強くない
- Redis などが有名
キーバリューストアとワイドカラムストア
データ構造の違いを深堀りします。
- 1 つのキーに対して 1 つの値をとる
- いままでの DB との違い:バリューに型の定義がない
- いろいろな型が入る
- どういう値がストアできるかはデータベースによって違うので注意
- プログラミング言語のドライバが、プログラミング言語のデータ型に置き換える
- 1 つのキーに対して複数の列 ( ex. 多次元配列のキー ) もとることができる
- 列の型は固定されておらず、列の数も自由
- 使わない列は RDB では明示的に NULL などにする必要があった
- サイズ
- RDB は空欄を含めたデータ容量が必要
- ワイドカラムでは空欄はデータ容量を消費しない
キーバリューストア
ワイドカラムストア
ドキュメント DB
次にドキュメント DB の特徴です。
- JSON のような階層構造があるデータに特化した機能
- 一次元のキーと値だけでなく、ネストしたキーと値も扱う
- 半構造データにおける開発生産性が高い
- MondoDB などが有名
ちなみに MySQL 8.0 / PostgreSQL 9.2 から JSON を扱えるようになったので、 RDB も進化していますね。
このほか、 KVS 、ドキュメント DB に続き、グラフ DB についても紹介いただきました。
CAP の定理
NoSQL データベースの多くに共通する分散アーキテクチャの場合、 CAP の定理を意識する必要があります。
- 分散システムにおいて以下の 3 つのうち最大 2 つまでしか満たすことはできないという定理
- C (整合性)
- すべてのノードで同時に同じデータが見える
- A (可用性)
- 単一障害の一部のノードで起きた障害で処理の継続性が失われない
- P (分断耐性)
- ノード群のネットワークが分断されても正しく動作する
- C (整合性)
- どの 2 つを重視するのか、目的によって異なる
- CA 特性
- RDB(OLTP)
- CP 特性
- Redis 、 MongoDB
- AP 特性
- Cassandra
- CA 特性
NoSQL のメリット、デメリット
NoSQL にも、もちろんメリットとデメリットがあります。そこから判断するには、誰にとってのメリット・デメリットなのかが重要です。
- アプリケーション開発者にとって
- メリット
- データモデルを選択できる
- スキーマを定義せずにデータを格納できる
- ドキュメント DB ならば高速な開発が可能
- デメリット
- 各種機能が乏しい(特に KVS とドキュメント DB )
- トランザクションや整合性を保つ機能が使えない(特に KVS とドキュメント DB )
- スキーマ管理をしないとデータの中身がわからない
- メリット
- データベース管理者にとって
- メリット
- 性能増強が容易(特に KVS とドキュメント DB )
- 高可用構成を簡単に構築できる(特に KVS とドキュメント DB )
- デメリット
- トラブルシューティングが難しい
- 運用に関する機能が乏しい
- メリット
ここまでの分類をまとめると、次の図のようになります。
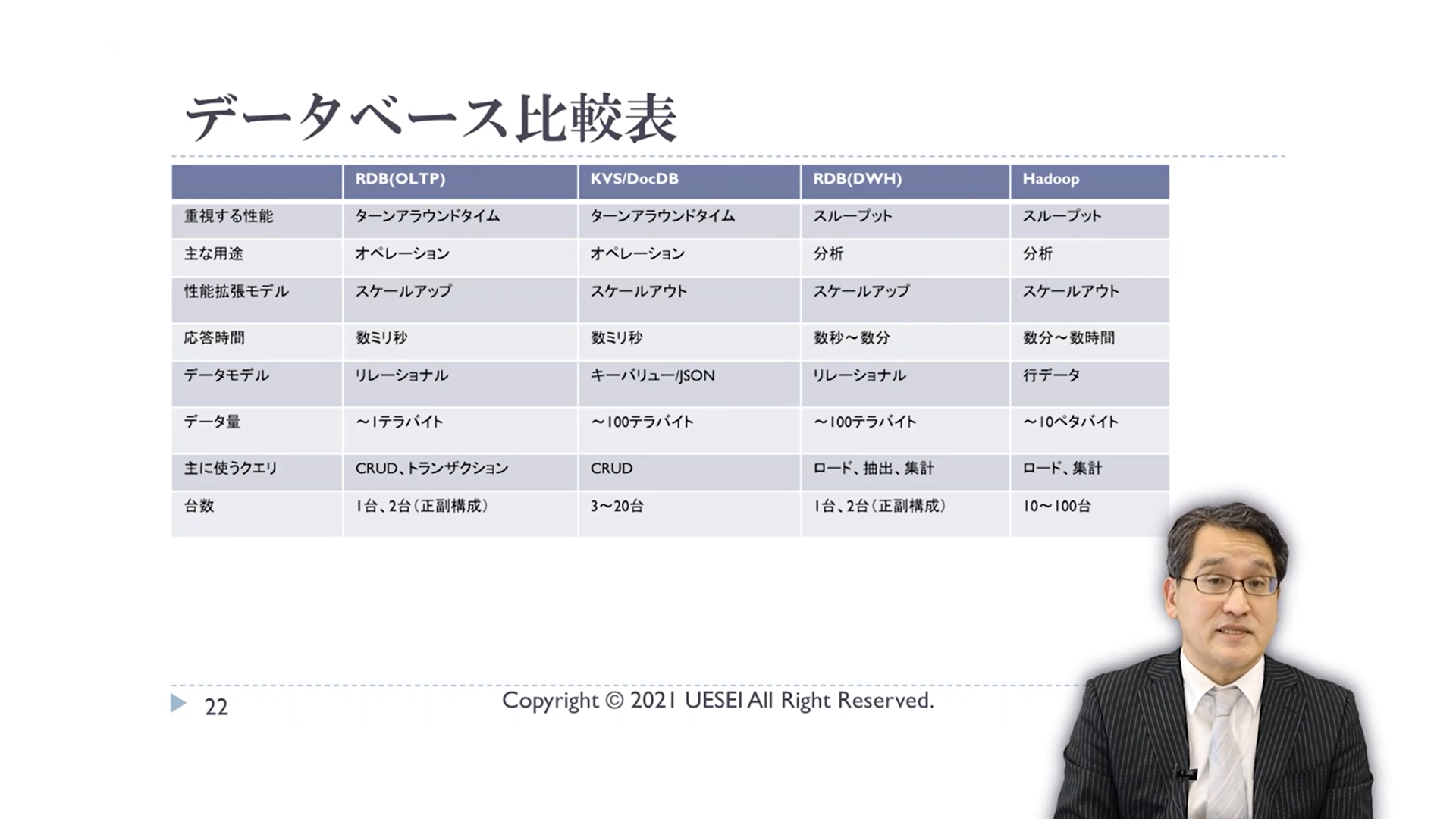
MongoDB を操作してみる ( ドキュメント DB )
ここからは実際に NoSQL データベースを操作する時間です。比較として MySQL の操作を見たあと、データモデルごとに代表的な NoSQL データベースを操作します。
まず、ドキュメント DB の代表格である MongoDB です。
MongoDB では、 RDB のテーブルの代わりに、コレクションを作ります。
- コレクション作成
> db.createCollection('coltest') { "ok" : 1 }
続いて、簡単な CRUD 処理をやってみます。
- POST データの追加
> db.coltest.insert({ name: 'suzuki', age: 45, blood: 'O' }) WriteResult({ "nInserted" : 1 }) // もう 1 つ追加。前のデータとキーが同じである必要はない > db.coltest.insert({ name: 'yamada', age: 30, tel: '090-0000-0000' }) WriteResult({ "nInserted" : 1 }) - GET データの参照
> db.coltest.find() { "_id" : ObjectId("60068c6d9855db4d1205dbd5"), "name" : 'suzuki', "age" : 45, "blood" : 'O' } { "_id" : ObjectId("60068c6d9855db4d1205dbd6"), "name" : 'yamada', "age" : 30, "tel" : '090-0000-0000' } // ObjectId が主キーのような役割 // 検索条件は find の引数に JSON で指定 > db.coltest.find({ name: "suzuki" }) { "_id" : ObjectId("60068c6d9855db4d1205dbd5"), "name" : 'suzuki', "age" : 45, "blood" : 'O' } - UPDATE データの更新
> db.coltest.update( { name: 'suzuki' }, // SQL の WHERE に相当 { $set: { blood: 'A' }} // 更新する Key, Value ) WriteResult({ "nMatched" : 1, "nUpdated" : 0, "nModified" : 1 }) - DELETE データの削除
> db.coltest.remove( { name: 'suzuki' } ) WriteResult({ "nRemoved" : 1 })
どちらかというとプログラミングに近いクエリの書き方ですね。
またテーブルとカラムの定義のようなものがなく、コレクションにそのまま投入できるのは面白い特徴です。
なお MondoDB には Web 上で試せる playground が幾つかあります。その中でも下記はデータが既にあり、サポートしているクエリが豊富だったため、試してみたい方にはオススメです!
Redis を操作してみる ( KVS )
次に、 KVS の Redis です。 Redis はキャッシュのデータストアとして使うことが多いものですね。
Redis では、テーブルやコレクションではなく、データベースがそれにあたり、その中に直接キーと値を入れていきます。
デフォルトで、 1 〜 15 という名前のデータベースが作られています。データベースを使うには SELECT でこの番号を指定します。
> SELECT 15
OK
同じく CRUD 処理を見てみましょう。 Redis にも Web で実行できるサンドボックスがあるので、ぜひ以下のコマンドはご自身でも試してみてください。
- POST データの追加
- SET を使う
- KVS なので、キーと値をセットで指定
- 下記では test がキー
> SET test "HELLO, World!!" OK - GET データの参照
- GET を使う
> GET test "HELLO, World!!" - DELETE キーの削除
> DEL test (integer) 1 > GET test (nil)
また、キーの有無や、どのキーを使っていたのか、確認するときは KEYS を使います(全件は * 。ただし件数が多いときには注意)。
> KEYS foo
1) "foo"
> KEYS *
1) "hoge"
2) "foo"
> KEYS bar
(empty list or set)
このあとグラフ DB の Neo4j でも同じような操作を行い、このコースは修了しました。
まとめ
このコースでは NoSQL の登場の背景、 NoSQL の種類、 NoSQL データベースごとの特徴や、実際の操作で SQL との違いを学びました。
システムが大規模化するのに合わせて RDB の限界があるのは、先日の Slack のテックブログで生々しく書かれており、そこには NoSQL / NewSQL への移行・併用は非常に抵抗が強いことも伺えました (結局、 Slack は Vitess という MySQL 向けのクラスタリングソフトを採用 [シャーディング用途]) 。この苦悩はどんなアプリケーション開発者や DBA も悩まされるものです。
NoSQL という言葉が登場して以来、長く時間が経過しましたが、モバイルネイティブ、スタートアップの急成長、コロナ禍などによりインターネットで圧倒的なトラフィックが生まれ、システムの大規模化が進む中、改めて NoSQL には何が出来て、何が不得意なのか、学べたのは貴重でした。
今度は Redis や MongoDB をどこで使うのか、構成例などをもとに学びたいですね!
label SEカレッジを詳しく知りたいという方はこちらから !!
IT専門の定額制研修 月額28,000円 ~/ 1社 で IT研修 制度を導入できます。
年間 670 コースをほぼ毎日開催中!!
SEプラスにしかないコンテンツや、研修サービスの運営情報を発信しています。