機械学習 モデル の作り方と必要な基礎知識|研修コースに参加してみた

今回参加したコースは 機械学習 モデル の作り方と必要な基礎知識 です。
SEカレッジではこれまでにも体験型で機械学習のモデルを作るコースはありましたが、このコースではモデルを作る流れや、必要となる統計と機械学習の基礎知識を学びます。
ちなみに、私は統計学と機械学習の関係をあまり考えたことがなかったのですが、このコースに参加して理解できました!
そして、モデル作成はノーコードで作成できたのですが、そのあとの質疑応答で講師の植田さんから衝撃のお答えが! これはちょっと AI 開発が変わっているのかも知れません。その内容は … 記事の最後で。お楽しみに!
では、どのような内容だったのか、レポートします!
もくじ
コース情報
| 想定している受講者 | プログラミングの基本知識がある方が望ましい |
|---|---|
| 受講目標 |
|
講師紹介
講師は AI 機械学習分野でご登場が多い 植田崇靖 さんです。

IoT / AI から Web までフルスタックな開発経験をもとにした、幅広く実践的な研修コースを開発
以前にも AI 関連のコースでレポートしていますので、ぜひご覧ください。
3 時間で学ぶ!AI・機械学習 入門 研修コースに参加してみた
G検定で学ぶ AI の体系と基礎知識 「オンライン」研修コースに参加してみた
統計分析の基礎知識
統計における 平均、分散、標準偏差、共分散 の指標を説明いただいたあと、早速、統計分析を学びます。
ちなみに、なぜ統計を学ぶのかというと、
- 機械学習でいきなり大量のデータを扱おうとすると、時間とリソースを食われる
- その前に統計分析で標本を抽出してデータ特性を分析するほうが速い
- 統計分析で使う統計手法が機械学習の手法にも入っている
と植田さんからお話いただきました。なるほど!
- 特定の集団のデータを集めて、その特徴や傾向を表す
統計学とは
- 母集団からデータを取捨選択して、標本を抽出
- 標本の特性を明らかにする (ex. 年齢と購入額の関係)
- 記述統計学 という
- 標本の特性結果から母集団の特性に合致するか推定・検定する
- 予測統計学 という
統計分析の進め方
代表的な統計手法
- 相関関係
- 2 つ以上の変量の相関関係の分析
- ex. アイスクリームの売上と温度と関係があるかどうか
- 単回帰分析
- 1 つの値からもう一方のデータの値を予測する
- ex. 温度からアイスクリームの売上を予測する
- 重回帰分析
- 2 つ以上の値から特定のデータの値を予測する
- ex. 最高温度、平均温度からアイスクリームの売上を予測する」
- 判別分析
- 属性がついたデータをもとに、新しいデータがどの属性なのか予測する
- 時系列分析
- 規則的に連続するデータから未来を予測する
正規分布
一応、復習ということで、正規分布についても補足いただきました。
- 色々な事象のデータの分布はだいたいこうなる (ex. テスト結果や身長のデータ分布など)
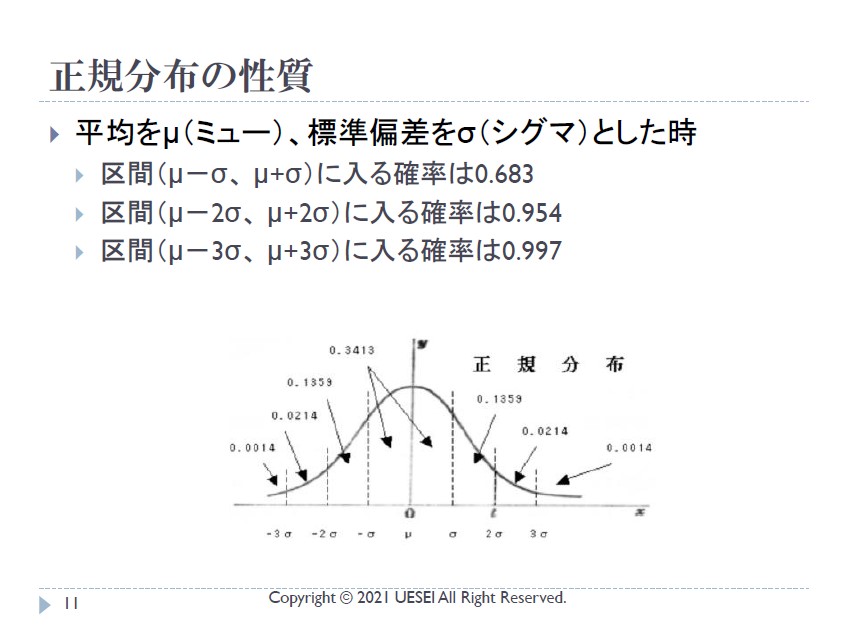
正規分布とは
そのほか統計学で出てくる用語、内挿、外挿を解説いただき、次は機械学習の基礎知識に進みます。
機械学習の基礎知識
機械学習の基礎知識と機械学習のアルゴリズムは 3 時間で学ぶ!AI・機械学習 入門 研修コースに参加してみた でも詳しくレポートしていますので、ぜひご覧ください。
ディープラーニング
ディープラーニングは、多層(狭義では 4 層以上)のニューラルネットワークによる機械学習手法ですが、従来の機械学習とは大きな違いがあります。
- 従来の機械学習:どの部分に着目するのか(特徴量設計)を人間が定義
- ディープラーニング:学習データから自動的に特徴を抽出する
続いて、そのディープラーニングの基礎を解説いただきました。
- 画像認識のコンテストで圧倒的な成績で優勝したことから広まった
- コンピュータの処理速度が上がり、インターネットによりデータも大量に収集できるようになったことが背景にある
- ニューラルネットワークの層を増やすと有益ということがわかってきた
- 複雑な場合はどんどん層を深くしていく
- 組み合わせの仕方を工夫する
- CNN (畳み込みニューラルネットワーク)
- 画像認識や物体認識などに有効
- RNN (再帰型ニューラルネットワーク)
- 音声や動画などに有効
- CNN (畳み込みニューラルネットワーク)
機械学習の基礎知識のまとめとして、ほかのデータ分析手法と比べた特徴をまとめて頂きました。
- 学習(機械学習モデルの作成)には時間がかかる
- 機械学習モデルができれば予測は一瞬
- 特徴量設計により精度が変わる
- ディープラーニングでは特徴量設計が必要ない
なお、ディープラーニングで特徴量が自動で抽出されるといっても、データやパラメータは人間が決めなくてはいけないというのは従来と一緒で、そのあとのどの部分に注目するかが自動になることだと植田さんは注意しました。
MatrixFlow を使って機械学習モデルの作り方を学ぶ
お題をもとに機械学習のモデルをノーコードで開発できる MatrixFlow を使って、実際に作り方を学びます。
- あるコンビニエンスストアで最適なアイスクリームの仕入れを行いたい
- 最高温度と平均温度に関連がありそう
- 最高温度と平均温度の予測から仕入れるアイスクリームの数量を最適化したい
- ある工場で製造スピードを上げたいが、不良率は下げたい
- 温度と製造スピードが不良率に関係していそう
- その日の温度に応じて、製造スピードを設定したい
お題
機械学習(教師あり)の一般的な作り方は次のとおりです。植田さんに MatrixFlow の画面を共有頂きながら、用意頂いたデータセットをもとに実際に作っていきます。
- データの準備
- 収集するデータの検討
- データの収集
- 後からあのデータもとっておけばよかったとなると手戻りになるので、多めにパラメータを取りがち
- 機械学習の手法(アルゴリズム等)の選定
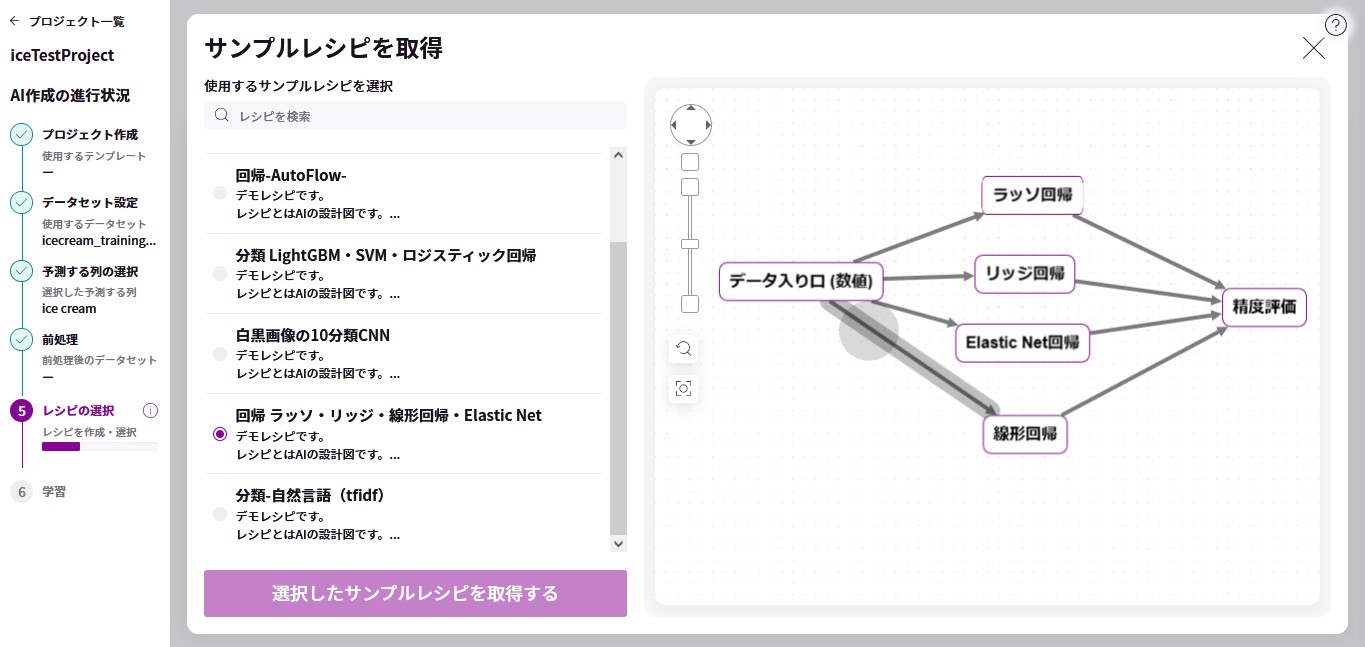
- 前処理
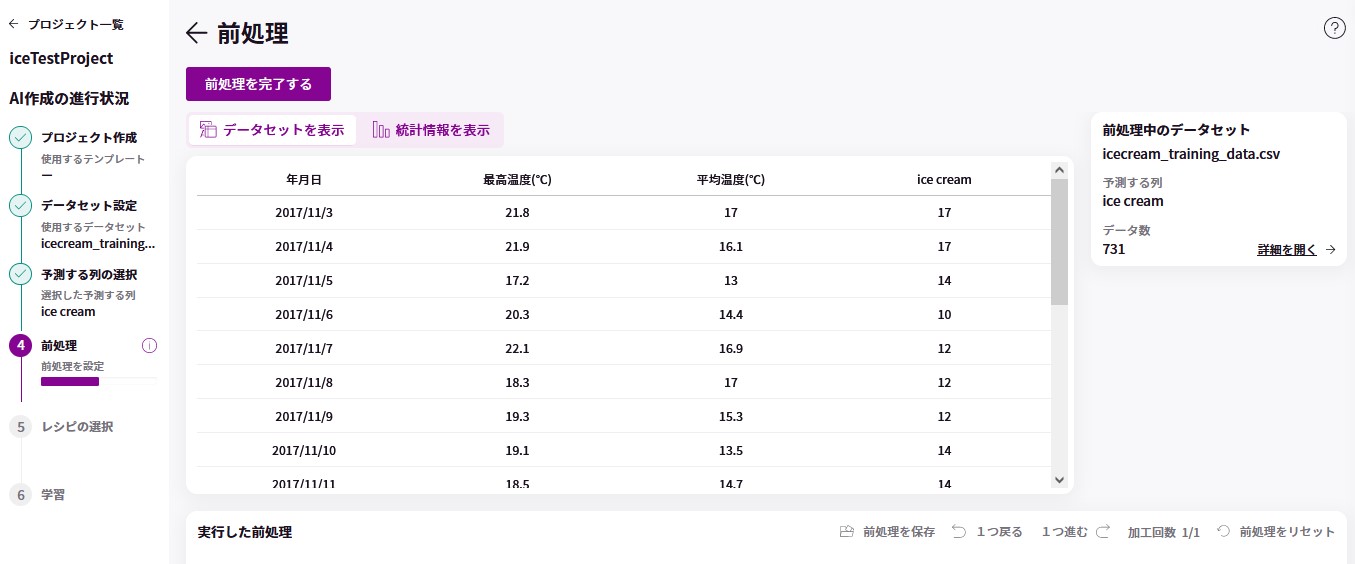
- 必要なデータの選別
- 変化のないデータを削る、など
- データラングリング(データクリーニング、データクレンジング)
- データを整える
- データの拡張
- データが足りなければ増やす
- 学習、評価用にデータを分割
- データ全体を トレーニングデータ( 9 割ぐらい)/ 精度検証データ / テストデータに分ける
- 必要なデータの選別
- モデルのトレーニング
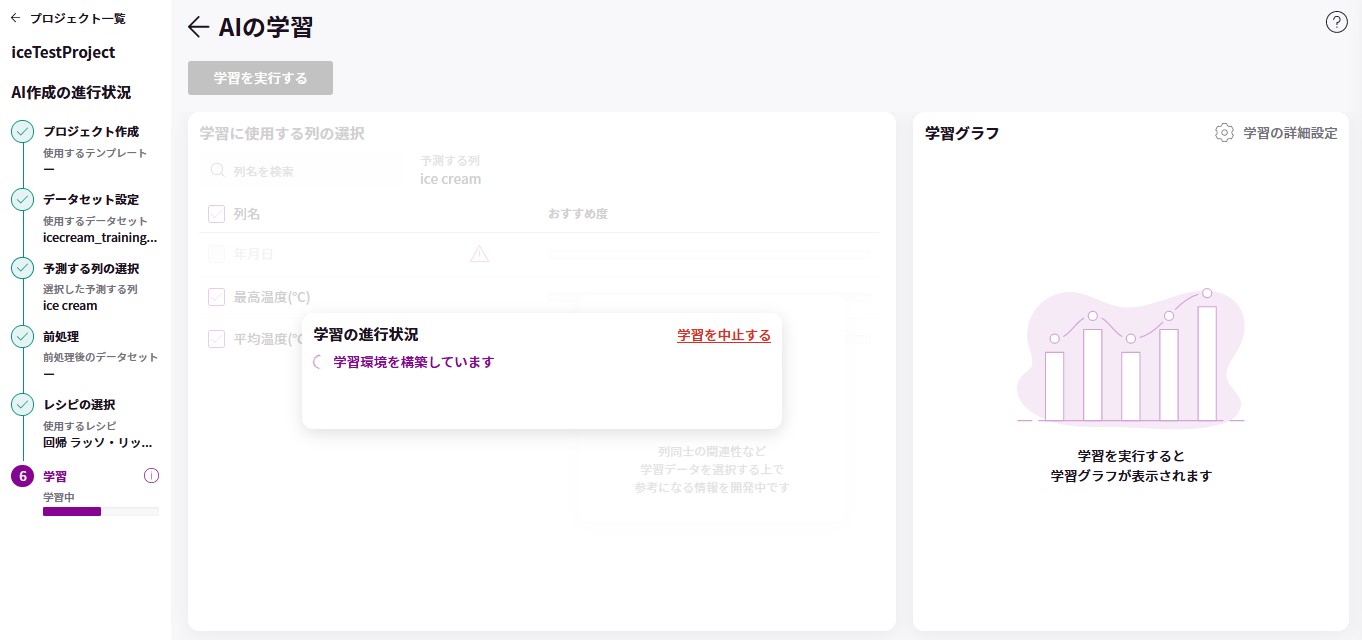
- ハイパーパラメータのチューニング
- 学習
- モデルの評価
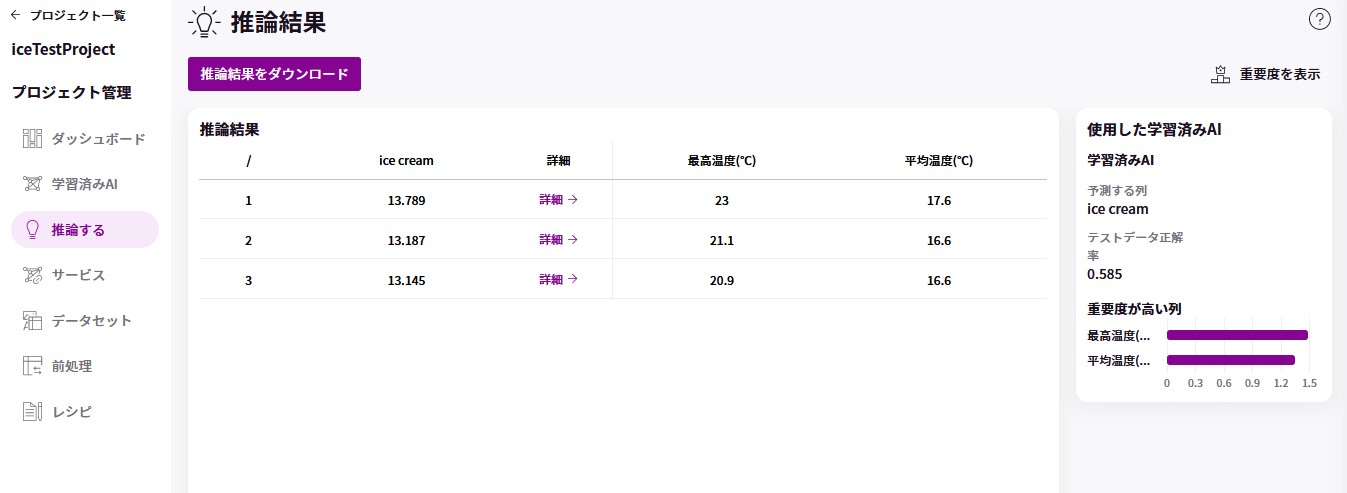
- 推論
- 2 . 〜 5 . を繰り返す
- 最適なモデルを選ぶ
- アルゴリズムを複数組み合わせることもある
- 納品、本番運用
- 選択した学習済みモデルを本番環境にデプロイして運用
- API として呼び出すことが多い
- 選択した学習済みモデルを本番環境にデプロイして運用
ハイパーパラメータのチューニングまで、なんと MatrixFlow が自動でやっていて、何も考えずとも最適化してくれました。こりゃすごい …
その他、ノーコードで機械学習モデルが開発できる Amazon SageMaker や Azure Computer Vision などのクラウドサービスを紹介いただき、コースのプログラムは修了しました。
質疑応答 ~ ノーコードだけで 98 % の精度を出せる
このあと質疑応答になったのですが、受講者から興味深い質問があり、さらに植田さんから衝撃的なお答えをいただきました。
Q
プログラミングなし、ノーコードだけでも AI の精度は上げられますか? 例えば、ノーコードで PoC してから、さらに精度を上げるには Python などを使うような作り方になるのでしょうか?
A
先日、担当した案件で、実際に MatrixFlow ではないツールを使って、プログラミングなしでも 98 % の精度に上げることができて納品しました。実は、今は Python など手段が問題ではなく、どのデータを、どれぐらいの量を集められるかが一番重要になっています。その次に重要なのが、アルゴリズムと、そのパラメータ設定がわかるようになることです。
Q
納品時にはどれぐらいの精度が求めれるのでしょうか?
A
一概には言えませんが、 96 % ~ 97 % ぐらいは出せないと公開は難しいとお考えください。
ノーコードは PoC だけで使うものだと思っていたのですが、そんなことは無くなっていたのでした !!
まとめ
このコースでは機械学習モデルを作るのに必要な統計と機械学習の基礎知識を学び、実際にノーコードツール MatrixFlow を使って、機械学習モデルの作り方を学びました。
最後の質疑応答にもありましたが、今はノーコードツールやプログラミングの手段の問題ではなく、今回学んだ基礎知識がより重要になっている、ということがわかりました。ということは、統計なりデータサイエンスの領域の数学は私にはかなり難しい … ので、やっぱりこれは逃げられず、勉強せねばいけないのでした。
それはさておき、基礎知識を総覧する上では、とてもテンポよく学べましたので、これから学ぶ方にはとてもオススメです !!
label SEカレッジを詳しく知りたいという方はこちらから !!
IT専門の定額制研修 月額28,000円 ~/ 1社 で IT研修 制度を導入できます。
年間 670 コースをほぼ毎日開催中!!
SEプラスにしかないコンテンツや、研修サービスの運営情報を発信しています。