3時間で学ぶ!AI・機械学習 入門 研修コースに参加してみた

今回参加したコースは 3 時間で学ぶ! AI・機械学習です。
「 AI や 機械学習 ってどんなものか教えて?」と IT 以外の業界のご友人もしくはご家族から質問されると、皆さんはどのように説明されますか?
私はゴニョゴニョ言っておしまいにすると思います!
このコースでは、そんな「なんとなくは知っているけれど、実際のところはよくわかっていない」AIや機械学習について、体系的にわかることはもちろん、ちょっとした機械学習のアルゴリズムから開発の進め方まで「チョットワカル」と言えるようになるものでした!
では、コースの内容をレポートします!!
もくじ
コース情報
| 想定している受講者 | AI についてはじめて学ぶ人 |
|---|---|
| 受講目標 |
|
講師紹介
登壇されたのは、この参加してみたレポートでは初めてのご登場、植田 崇靖さん です。
コースの中ではスライド 1 枚 2 行で、とてもアッサリと自己紹介されたのですが、そのスライドには一つだけ動画が紹介されていました。植田さんが開発されたのですが、これがまた面白いものでした!
人間の動きに合わせて、台車が追従するのです。いやいやスゴイ。
ちなみに、SEカレッジでは植田さんに 2 つの IoT のコースをお願いしており、いずれも人気です!
今日のコースは、決定木やランダムフォレストなど機械学習アルゴリズムを詳しく扱うのではなく、どのようにデータ分析するのか、その流れを GUI で簡単にできるツールを紹介します、ということでスタートしました。
AI(人工知能)とは
まずは、「そもそも人工知能とは何か」という解説です。
- 人工知能とは
- 人間の知能そのものを機械で作る
- 人間が知識を使ってすることを機械にさせる (単機能)
- 画像の中から指定されたものを抽出
- 自然言語 OCR 、理解、音声化・発話(スマートスピーカーや音声アシスタントなど)
- 画像認識系の利用、投資が大きい
音声、言語処理などなど、いっぱいある AI の分野の中でも、画像認識の市場が大きいとはちょっと知らなかったです。
AIの歴史
続いて、AI の歴史が紹介されました。これまでの他の AI に関する研修参加レポートでも触れていますが、現在は「第 3 次 AI ブーム」です。
- 第 1 次 AI ブーム
- 1950 年代後半~ 1960 年代
- 推論・探索が研究の中心
- ゲームやパズルを解く(トイプログラム)
- チューリングテスト(人間が相手からの応答を「機械によるものである」と見極められるかを試すテスト。AI の完成度を測るバロメーターとされる)
- 当時は、PC が低性能だったため、現実の複雑な問題は解けなかった → ブーム終息
第 1 次 AI ブームの頃によく用いられていたアルゴリズムの 1 つである、「探索木」も紹介されました。
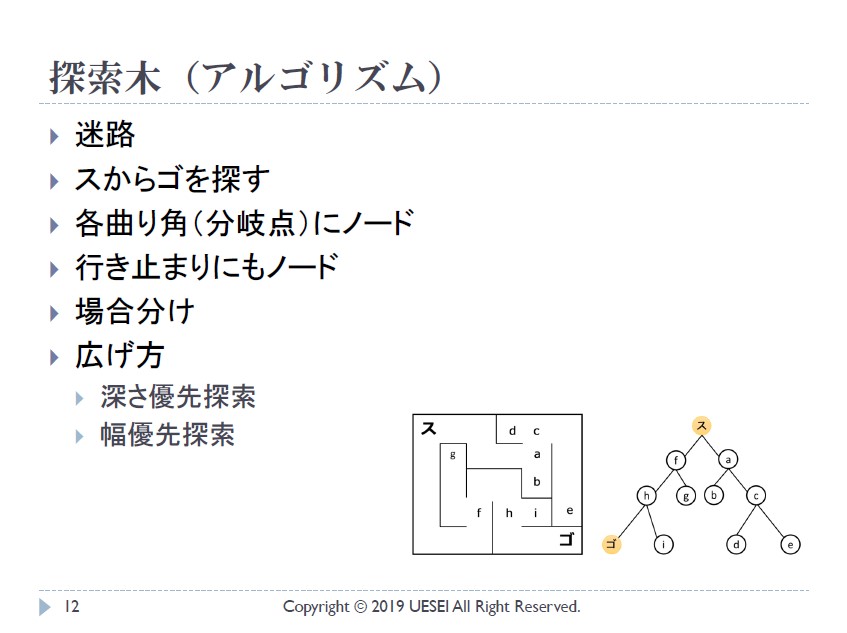
- 第 2 次 AI ブーム
- 1980 年代
- (専門家の)「知識」を入れる
- エキスパートシステム
- 専門家の意志決定をコンピュータで模倣することを目指す
- ex. MYCIN: 簡単な質問を繰り返し、細菌をあてる
- 69 % の精度 (専門家で 80 % )
- どのように知識を記述するのかが難しい
- 増え続けるデータの管理が困難(記憶容量の制約)
- 1995 年頃に終息
- 第 3 次 AI ブーム(現在)
現在の AI は、音声認識、画像認識やレコメンドなどに加えて、たとえば、感性処理 (言葉などから喜怒哀楽(感情)の判別 ) など様々に活用されています。
機械学習の基礎
機械学習とは? をざっくり解説いただきました。
- センサーなどで収集したデータからパターンを見つけて推論する研究
- 機械学習は AI の中の一つ
- 深層学習 (ディープラーニング) はその中の一つ
- 機械学習をデータの種類によって分類
- 教師あり、教師なし
- 答え (ラベル) があるかどうか
- 教師あり、教師なし
- 機械学習を問題の解決によって分類
- 回帰分類
- クラスタリング
- 機械学習のプロジェクトのほとんどは教師ありのデータを使って、回帰や分類する仕事
教師あり、教師なし学習
先に紹介頂いたものを、掘り下げていきます。
- 教師あり
- 気温とアイスの過去の売上から、アイスの売上を予測する
- アイスの売上がラベルデータ
- 傾向を分析する
- これは回帰
- たくさんの犬の写真から、たくさんの動物が写った写真から犬を特定する
- 犬の写真がラベルデータ
- 分類する方法を分析する
- これは分類
- 乳がんの検査はどっち?
- 気温とアイスの過去の売上から、アイスの売上を予測する
- 教師なし
- ラベルがないデータから特徴を見出して分類する
- クラスタリング
- どちらでもないのが強化学習
- 失敗したら罰を与えることによって、学習が補正される
ここでこの強化学習について、その驚異的な学習スピードがわかる動画を紹介頂きました。(植田さん、いちいち印象に残りやすい)
- インベーダゲーム
- ボールを打ち返すところが最初はランダム
- ボールを落とすと罰を与える
- 自動運転
- 道路を画像認識させる
- ハンドルやアクセルをランダムで操作
機械学習のアルゴリズム
続いて、機械学習でよく用いられるアルゴリズムが紹介されました。

ただ、ここで植田さんから大正コソコソ噂話ならぬ、現場話が差し込まれました。
「パラメータや変数をちょっと編集するだけ」
ナント!
ただし、「どんなアルゴリズム ( = 解決法) があるのか知っていて、それを問題に合わせて使えることが重要です」というお話でした。
ということで、どんなアルゴリズムがあるのか、決定木、ロジスティック回帰、k近傍法などなど解説いただいたのですが、ここでは抜粋して紹介します。
- ランダムフォレスト
- 分類や回帰で使う
- 決定木を多数作って多数決または平均値
- サポートベクターマシーン
- 一番良く使われる
- 分類や回帰どちらでも使われる
- データをわける線 (曲線直線問わず) を 2 つ作る
- それぞれのデータから等距離にあるものを割り出す
- ニューラルネットワーク
- 脳のニューロンがモデル
- 様々な入力を受け取り、なんらかの重み付けをしながら次の層に出力
- ディープラーニング
- 3 層以上のニューラルネットワークが重なったもの
- ある画像認識コンテストでトロント大が採用して優勝した
- 行列計算で行なっている = 3 次元 ( x, y, z ) 処理が速い GPU が効く
- CNN 畳み込みネットワーク
- 画像
- RNN
- 多次元
機械学習の特徴
アルゴリズムに関わらず、機械学習のプロジェクトには共通点があります。
- 学習は時間がかかる
- (学習が終われば)予測は一瞬
- 深層学習(ディープラーニング)は教師ありなしなど関係がない
- ただしディープラーニングは計算量がハンパない
そのほか、機械学習とあわせて使われる統計とその手法について、機械学習とはそもそも目的が異なること、使いみちも触れていただきました。
機械学習を使った開発の進め方
続いて、機械学習を使ってどのように開発するのか、実際の演習ケースをもとに、その流れを紹介いただきました。

- データの準備
- 収集するデータの検討
- データの収集
- この工程が後に影響してくる (ここで失敗すると、すべて失敗する)
- どのデータを利用するか、が非常に重要
- どのデータが最終的な結論に結びついているかをしっかりヒアリング
- マンパワーの 8 割くらいがここにかかる
- 手法の選択
- 機械学習の手法(アルゴリズムなど)の選定
- 基本は全部やって、作ったモデル同士を比べる
- 前処理
- 必要なデータの選別
- 相関が強くないデータは使わないことが多い
- データラングリング(データクリーニング、データクレンジング)
- 何らかの影響でデータが欠損したり異常値がある → 適当な数値(平均値など)を入れたり項目自体を削除
- データ拡張
- 画像データを扱う場合に実施することが多い
- 既存のデータを加工(画像処理など)して増やすこともあるが問題が多いので、あまりやらない方がよい
- データ分割
- トレーニングデータ
- 評価データ(今回は使用しない)
- テストデータ
- トレーニングデータの 90 % をモデル用、トレーニングデータの 10 % をテストデータとする
- 必要なデータの選別
- モデルのトレーニング
- 学習
- モデルの評価
- アルゴリズムを利用してモデルを作り、精度をチェックして最適なものを選ぶ
- 納品、運用
- デプロイ -> Web API のように使う
このあと、自身の PC を使ってローカルで開発するときに使うツール or クラウドを使って開発するときのツールを紹介頂きました。
- ローカル PC で開発
- Python や Anaconda 、また Python の NumPy, Scikit-learn やディープラーニングの Tensorflow などのライブラリを使用 (ここでは割愛)
クラウドサービスでのデータ分析
続いて、クラウドサービスについていくつか紹介頂いたのですが、私があまり知らなかったものを、ここでは紹介します。
このコースでは、先のケースで出てきたデータをもとに、MatrixFlow を使って植田さんにデモして頂きました。
- MatrixFlow
- ノンプログラミングで使える
- レシピ(モデル)が用意されている
- 最適なアルゴリズムとパラメータの組み合わせを簡単に探せる
- 推論には推論用データ(プレディクトデータ)を使用
- メールアドレスとパスワードの登録で利用可能
- 無料版はアルゴリズムを選べない
Python のコードが一つも出てこず、PoC の前段階として使えるかなぁ、という印象を受けました。

講義の最後に、 AWS 、 GCP 、Azure にも、機械学習サービスがあることを紹介して、このコースは修了しました。
まとめ
このコースでは、タイトルの通り 3 時間で AI や機械学習について、その全体像がわかりました。
体系的にまとめて頂いたことと、動画やデモを交えて頂いたので、あまり難しいと感じることもなく、また座学でもあまり退屈に思うことはありませんでした。
また、植田さんが開発されていることもあって、実際に現場で行われていることを、チョイチョイ紹介頂くので、それが刺激的でした。
これで私も家族や友人に、いい感じに説明できそうです!
label SEカレッジを詳しく知りたいという方はこちらから !!
IT専門の定額制研修 月額28,000円 ~/ 1社 で IT研修 制度を導入できます。
年間 670 講座をほぼ毎日開催中!!
SEプラスにしかないコンテンツや、研修サービスの運営情報を発信しています。