パフォーマンスチューニングの勘所 研修コースに参加してみた

今回参加した研修コースは パフォーマンスチューニングの勘所 です。
パフォーマンスチューニングというとSQLの改善というのが挙げられがちで、効果も発揮するのですが、このコースでは 「推測するな、計測せよ」 という鉄則通り、モニタリングから始めて、なぜこのパラメータをターゲットにして、なぜこの数値をメトリクスにするのか、それをRDBMSのアーキテクチャから解説いただきました。
講師の林さんの言葉通り、勘に頼ったチューニングではなく、アーキテクチャから体系化して理解したい方にはとてもオススメの内容です。
では、どんな内容だったのか、レポートします!!
もくじ
想定している受講者
| 想定している受講者 | データベース物理構成に関する用語、SQLに関する用語が理解できている |
| 受講目標 | データベース全体のパフォーマンス改善、劣化予防のポイントが指摘できるようになる |
講師紹介
登壇されたのは 林 優子さん です。前回 ハンズオンで学ぶデータベース障害のパターンと復旧 研修コースに参加してみた でもレポートしましたが、今回も参加された方に合わせた丁寧に解説いただきました!

Oracle認定講師としてExcellent Instructorを連続受賞した人気トレーナー。
Oracleだけでなく様々なRDBMSに対応し、内部構造もわかりやすく解説
というわけで、今回も参加された方の使っているRBMSを伺ってスタートしました。
参加された受講者が使っているRDBMS
- Oracle 9
- SQLServer 4
- MySQL 3
- DB2 3
状態の把握:モニタリング
パフォーマンスチューニングは勘に頼っている部分があるので、アーキテクチャから体系化してチューニングしましょう、というコースの狙いからモニタリングから解説です。
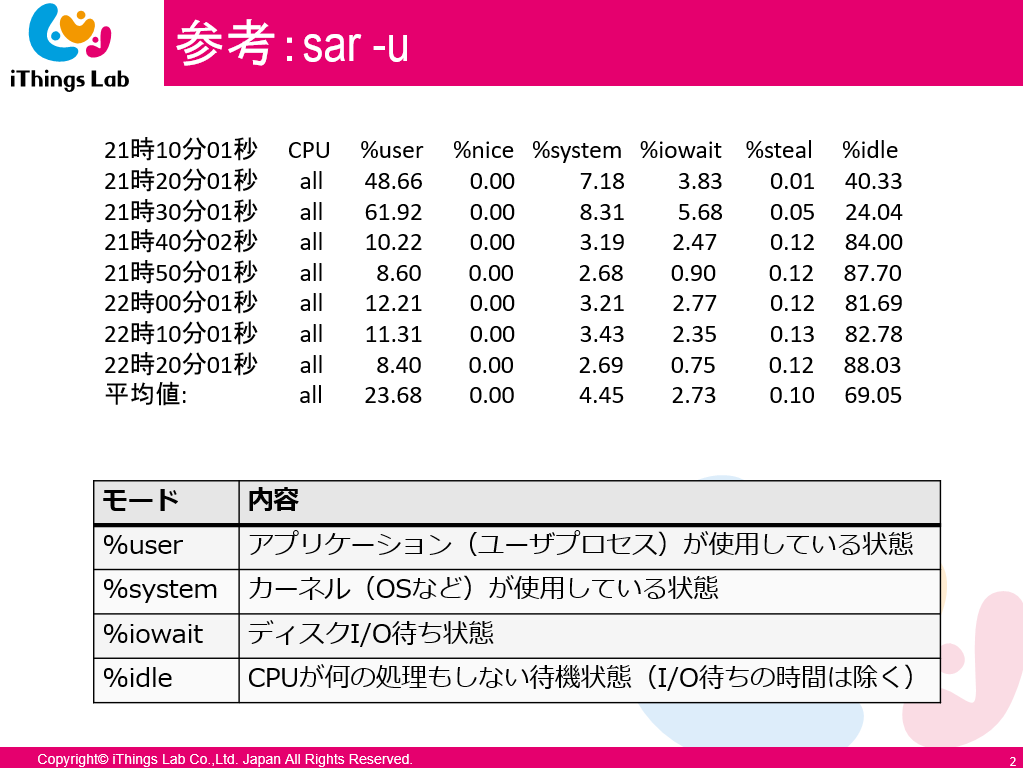
- まずはOSからモニタリングすること
- DBサーバーのOSのパフォーマンスを観測
- DBベンダーは DB:OS = 6:4 ぐらいがよいと推奨
- DBだけでなくOSもプロセスを動かしているので消費しています
%systemが上ってきたならば%iowaitを見て、ディスクI/Oを見ましょう
パフォーマンス劣化の原因
- ディスクI/O
- 競合による待機
ディスクI/Oは当然ながら、競合による待機、ロック待ちも注意です。メモリ高負荷を招き、全件検索が多いとそうなります。
今日はここを中心に解説されるとのことでした。
DBアーキテクチャとチューニングのポイント
では、なぜメモリ高負荷が起こるのか、アーキテクチャから解説いただきました。
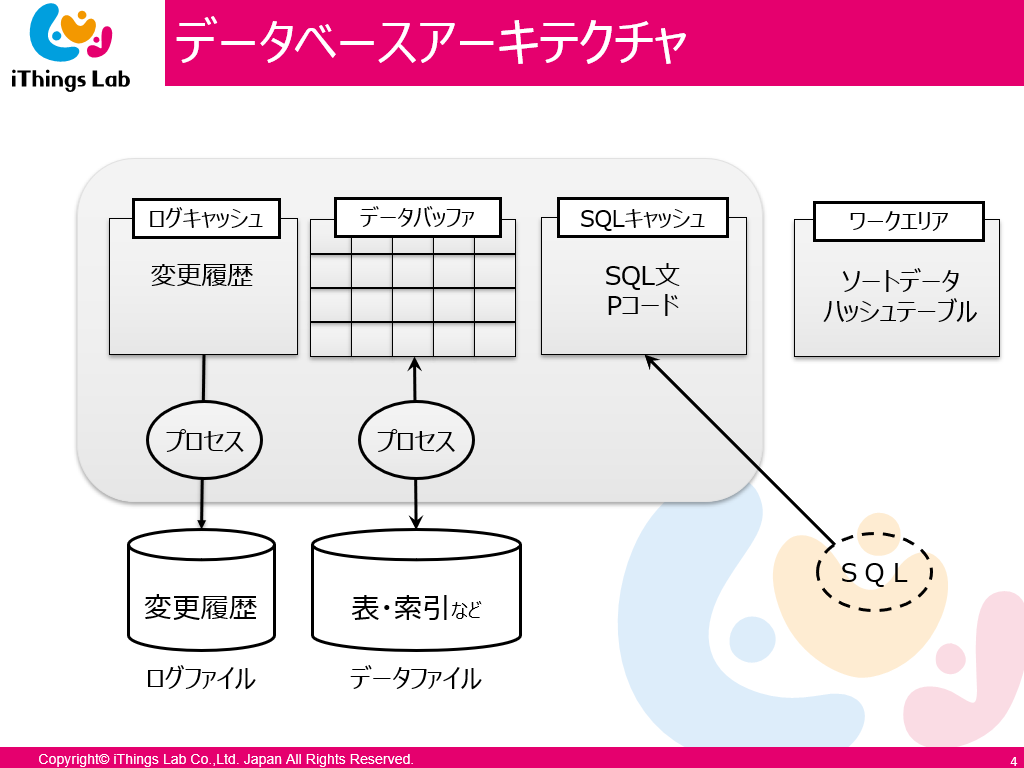
SQL解析
SQL発行 SELECT * FROM CUSTOMER WHERE no=123
- ワーカープロセスが動く // ワーカープロセスの呼称はRDBMSによって違う
- SQLを解析
- 構造解析
- ちなみに
SELECT *orSELECT (column)どっちが早い? - 実はあんまり大差はなくカラム指定のほうが零コンマ何秒早い
- ちなみに
- 最適化 (実行計画作成)
- メモリ上にある内部的なテーブル (データファイル) を見に行く
- いきなりディスクは見に行かない
- このコースではここをSQLキャッシュといいます
- 最適化というのは乗換案内アプリと同じで、コスト (所要時間) をみて最適経路を考える
- メモリ上にある内部的なテーブル (データファイル) を見に行く
- すでに実行したSQLがあれば、プログラムコード (Pコード) もキャッシュされているので、それを使って実行
- なのでメモリで共有しやすいSQLを書こう
- アプリケーション側でバインド変数、プレースホルダーを利用しましょう
- 実行段階でSQLキャッシュが無くなっていれば、空けるためにPコードを追い出す
- もし追い出したPコードを使うときは内部テーブルからRELOADする
- パフォーマンスチューニングの指標はこのRELOADを0にすること
- その上でSQLキャッシュを増やすかどうかを考えましょう
一旦ここまでのまとめ
- SQLを共有できていますか?
- 指標はヒット率
- 90%が目標
- RELOADが0か?
- 0じゃなければSQLキャッシュを増やす
ただしメモリは有限なので、SQLキャッシュを増やすと、バッファキャッシュなどが小さくなってしまいます。
自動チューニングの時代と言っても、ここまでやってくれないので、ここが基本です。
SQL実行
- バッファキャッシュにテーブルが無ければディスクにアクセス
- ブロックやページと呼ばれる単位でアクセス
- これがディスクI/Oの単位 (DB2を除きRDBMSのほとんどは8KB)
- 1レコード長が8KB以下ならどんなデータだろうがなんだろうがよい
- 見つけたものをメモリに上げる
- これが索引 (インデックス) 検索
- 一方で全件検索とは?
- 連続したブロック/ページ 8KB x 8 =64KB が1エクステント
- 1回で読みに行く単位が1エクステント
- この64KBにおさまるテーブルかどうかで分割するかどうかを検討する
- 全件検索が多い (例えばデータ解析) 場合、このエクステントもしくはブロック/ページサイズを大きくする
- 読み込んだ1エクステントのデータをバッファキャッシュに入れてロックしてから検索する
- 同時アクセスが多い場合、ロックと解放が繰り返され、CPUが上がる
- バッファビジーウェイト (buffer busy waits) と呼ばれる症状
- CPUが高負荷、ディスクI/Oは少ない、というのはだいたいこの症状
- バッファビジーウェイトが多発するようであれば索引検索に変えましょう
- それでも全件検索が必要な場合、バッファキャッシュ上のサイズの閾値を設けよう
- テーブルサイズが大きい場合、バッファキャッシュを食いつぶしてしまう可能性がある
- バッファキャッシュの**%以上のテーブルサイズを読み込む場合は、その**%以内で読み込んでは捨てています
- OLTP (INSERTやUPDATEなどが多い) 系のシステム は索引検索を使おう
- ヒット率を高めるためにはブロックサイズを小さくして、色々な種類のデータをメモリにあった方がヒット率が上がる
- INSERT が多発する場合、ブロック/ページへの書き込み待ちが発生する (バッファビジーウェイト)
- ブロック/ページサイズを小さくすると、違うブロック/ページにINSERTさせる
- OSによって処理できる単位が違うので注意しましょう (Windowsなら8KBが推奨される)
共有メモリ
今は大容量を扱えることになっているので、気にしないこともありますが、一応基本として紹介されました。
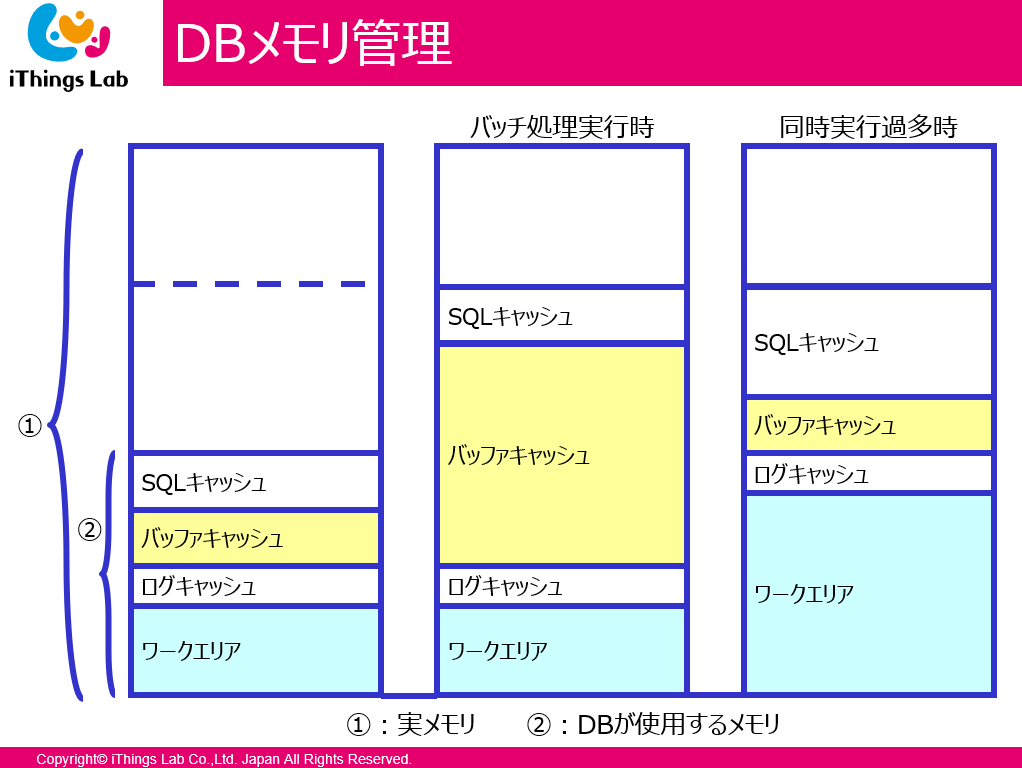
- DB以外のアプリケーション(OSなど)が動いている
- 昔は夜間バッチの際にはバッファキャッシュの割合を変えていた
- 昼間はSQLキャッシュやワークエリアの割合を増やしてヒット率を向上
- 夜間はバッチで大量にINSERTがあったり、全件検索をする場合、バッファキャッシュの割合を増やしたりしていた
SQLのチューニング
他コース (良いSQLと悪いSQL) があるので、深掘りしたい方はそちらへ! ここでは使う頻度の高いテクニックを紹介頂きました。

索引検索
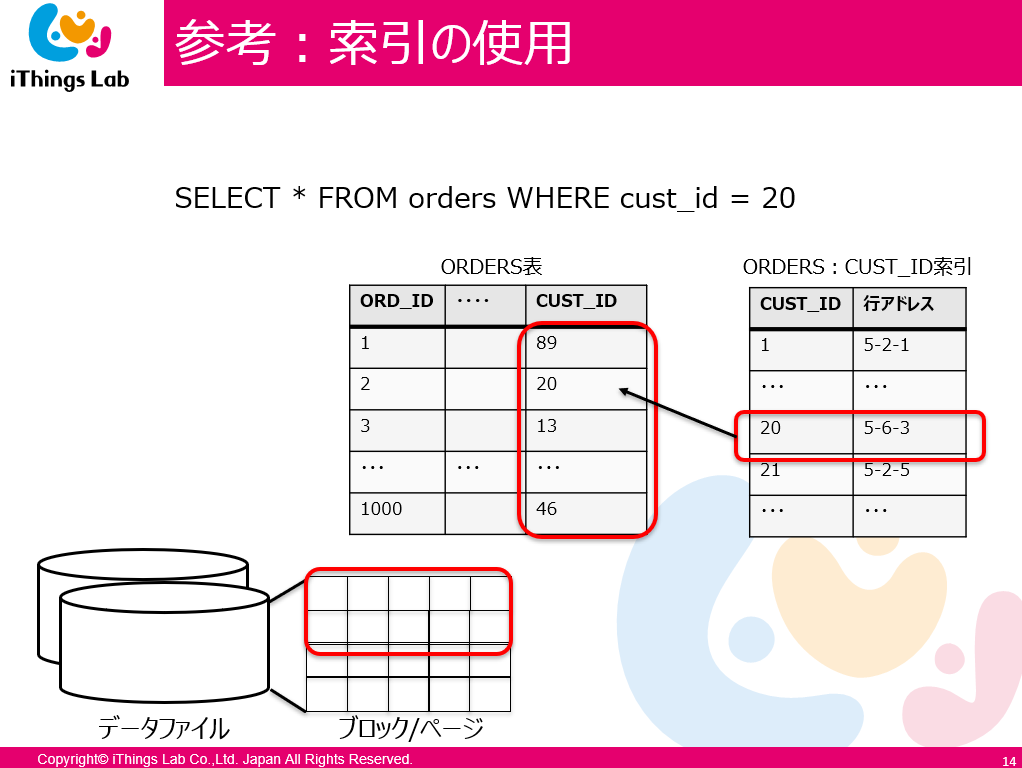
SELECT * FROM orders WHERE ORD_id=2ならスグに見つけたら終了できるSELECT * FROM orders WHERE CUST_id=20なら?- ソート済みの CUST テーブルを見に行ったほうがよい
- でも
CUST_id=100000なら? - そうならならいよう、BalancedTree を適用しておきましょう
- これが索引検索
hoge = 1,-> 索引検索が使えるhoge <> 1,-> 索引検索ではやらない // 全件と一緒なのでfuga LIKE 'A%',-> BETWEEN句と同じで前方一致は索引検索を使うfuga LIKE '%Z',-> 後方一致は索引検索を使わない- 前方一致検索と後方一致検索の速さの違いはここにある
- プライマリーキーにクラスタ索引 (値が小さい順に並ぶ) が適用されている場合
- 例えば商品コードというのがプリマリーキーになるが、数値での設定が望ましい
- M001T のようなコードはブブー、ダメです。。
- INSERT するたびにクラスタ索引を再構成している
- M と T のアルファベットで再構成してからINSERT
- 一度クラスタ索引を落として、再配置したほうが早い
- 例えば商品コードというのがプリマリーキーになるが、数値での設定が望ましい
索引検索をわかりやすくホワイトボードに書いて頂いたのですが、写真が撮れず、、ここではわかりやすく書かれている記事がありますので、それをご覧ください。
JOIN のチューニング
このパートでは実際に用意されたテーブルをもとにJOINを実行して計測してみます。
- SQL
- 実行計画
Rows や Bytes を見ると、72件のデータを抽出したいのに 918k を対象としてしまっているので、対象を絞りましょう。
- SQL
- 実行計画を見る
- TempSpc というカラムが追加されている
- ワーカープロセス (グループ・並び替え・結合) を行う仮想メモリ領域のこと
- 処理が多いので仮想メモリに追い出して実行している
- つまりはディスクI/Oが発生している -> この部分のSQLを見直す
- WHERE句などで918Kではなく36148だけを絞り込んで対象にしたい
- 結合をハッシュではなくWHERE句で絞り込んでネストループに出来ないか
- この処理が夜間バッチであればワーカーメモリを増やす設定が出来ないか
このJOINのチューニングポイントを解説頂いたところで、このコースは終了となりました。
まとめ
このコースではSQLも含めて、パフォーマンスチューニングのポイントをアーキテクチャから体系的に理解して、どのパラメータをどのようなメトリクスで測るのか、なぜ索引検索は速いのかなど、解説いただきました。
ホワイトボードで図を交えながら、とてもわかりやすく解説いただいたので、なぜそのチューニングテクニックが効くのか、理解できました! ちゃんとOSのモニタリングや、SQLの実行計画を見て考える癖をつけて行きます!
(私どもの製品ではORマッパーを多用しているので、それこそちゃんと計測せねば。。)
パフォーマンスチューニングはDBAの腕の見せどころの1つなので、構築設定だけでなく、これから腕を上げていこうとお考えのDBエンジニアにはとてもオススメです!!
label SE カレッジの無料見学、資料請求などお問い合わせはこちらから!!
label SEカレッジを詳しく知りたいという方はこちらから !!
SEプラスにしかないコンテンツや、研修サービスの運営情報を発信しています。