ハンズオンで学ぶデータベース障害のパターンと復旧 研修コースに参加してみた

今回参加した研修コースは ハンズオンで学ぶデータベース障害のパターンと復旧 です。
受講していると、ちょっと耳が痛い、どこからともなく頭痛がしてくる内容で、ちゃんと対策せねばという気持ちになりましたが、とはいえ、やらなきゃダメ、絶対、という高圧な口調ではなく、あくまで DB エンジニアとして誇りある仕事をしましょう、とソフトながら説得力のあるお話でした。
さすがです、林さん。
内容は、なぜその障害が起こるのか、アーキテクチャから解説いただいたので、ただの設定 Tips ではない知識が理解できました!
データベースの運用に携わる方であれば、ぜひ一度参加いただきたい内容です。
では、どんなコースだったのかレポートします!
もくじ
コース情報
| 想定している受講者 | SQL によるリレーショナルデータベース操作ができる |
|---|---|
| 受講目標 | 障害のパターンとその対応方法を理解する |
講師紹介
この参加してみたレポートでは初登場ですね。林 優子さん が登壇されました。講座では自己紹介もそこそこにコースをスタートされましたが、ここではもうちょっと詳しくご紹介します。

Oracle をはじめとしたデータベースのスペシャリスト。 資格書と対策研修で圧倒的な人気を誇る。 Oracle 認定講師を表彰する Excellent Instructor を連続受賞。
林さんと言うと、 オラクルマスター教科書シリーズ の執筆や Oracle University が毎年表彰している Excellent Instructor を 5 回も受賞した講師です。
SEカレッジでもデータベース分野で数多く登壇いただいていて、参加満足度がとても高い人気の講師です。
まず講座の前提から説明です。
- 事前アンケートには目を通していますが、期待した内容でなければ、いつでも言ってください
- RDBMS によってリカバリー方法が異なるので、考え方を学んでもえるとうれしいです
- Oracle から PostgreSQL など一通りできますので、お使いのもので教えてもらってもよいでしょうか?
- 手が挙がった内訳 (複数回答OK)
- Oracle ・・・5
- SQL Server ・・・5
- MySQL ・・・2
- DB2 ・・・1
起こりうるデータベース障害の種類
まずはデータベースにどのような障害が起こるのか分類です。

- 文障害~メディア障害までは、どのリカバリ系の研修コースでもやってます
- そこに含まれない、セキュリティ障害とパフォーマンス障害は DBA の実務上、とても影響が大きかったのでこれを中心にやります
セキュリティ障害
- SQLインジェクション
- Web サイトの何らかのフォームから
where句やorder_by句などが渡される - 例えば
:idという文字列が渡されるとどうなるのか WHERE句のFALSEを利用するWHERE emp_id = ' ' OR 'x'='x' /* employees という従業員テーブルがある想定 */- これが TRUE になって全レコードが指定されてしまう
対策

- バインド機構の使用
- プレイスホルダを使うのがオススメ
起こってしまったリカバリというより、障害を予防するという観点で必要です。
それ以外にも方法があるので、詳しく知りたい方はSEカレッジで開催している SQL インジェクション対策の講座に参加して下さい、とのことでした。
パフォーマンス障害
- パフォーマンスも悪くなると止まる = ユーザーには障害 (トラブル) と同意
- CPU高負荷が起こると止めたくないので、経過観察してしまう
- そうすると1時間ぐらい使ってしまう
対策
詳しく知りたい方は同じようにSEカレッジでパフォーマンスの講座があるので、ぜひそちらに、とのことで、ここではポイントだけ解説されました。

- 全件検索をやめましょう…
- 例えば
SELECTでもロックが掛かる - なのでユーザーの
SELECTが終わらないと共有メモリは空かず、ロック待ちが増える - ディスク I / O が無くても CPU が高負荷になってしまう
- 索引検索にしよう
- 例えば
障害の可能性を低くする
- DB 稼働を監視
- 例えば、アラートを出す CPU 使用率のしきい値
- 平常 -> アラート -> 警告 -> クリティカルなどで設定
- 例えばディスク障害は突然に起こったように見えるが、実は 1 週間前から兆候がでていたりする
- かつアクションプランも用意しておく
- RDBMS のバグレポートのチェック
- 毎日来るから見なくなるけど、 1 週間など定期で斜め読むなど習慣をつけましょう
- 林さんが遭ったツライやつ: 275 日たつと落ちるという OS のバグに遭った
- RDBMS のアーキテクチャを知りましょう // 後述
- 障害対応の訓練
- 1 年に 1 回はやりましょう
- 訓練内容
- 影響範囲の見極め 全ユーザーなのか一部なのか
- ユーザーには誰が連絡する?
- トラブルシュートしていない人がやること
- 障害レポートの掲載は誰が行うのか?
- 予め文章を用意しておくとよいです
- クライアントによって怒られる表現もあるので
- 例えば、金融機関向けには “緊急停止” という言葉を使うのは NG など
- RDBMS ベンダーの対応はだれ?
- 海外のサポートがいるので語学堪能な人がよい
- 日頃の付き合いの中で、ベンダーの上の人をおさえておくとよいです
- 障害対応するのは? インフラ? アプリ?
- 誰が指揮するの?
- 上司ですよね
- 再起動するぞ、というジャッジは上司じゃないと出来ません
- 回復->動作確認までで、どれぐらいの時間になるのか計測しましょう
- 影響範囲の見極め 全ユーザーなのか一部なのか
- その他
- Oracle にはログマイナーというユーティリティがあってログを見るだけなら出来ます
- 設定していないと見れない
- 技術的ではないけれど、重要です
- Oracle にはログマイナーというユーティリティがあってログを見るだけなら出来ます
ここは伺っていて、ちょっと頭が痛くなりました。。とはいえ、林さんから 「 DB にあるのはお客様の大切なデータなので、 DB エンジニアとして誇りある仕事をしたいものですね」 とおっしゃっていたのが、とても刺さりました。
また、サポートのお話を伺っていると、 OSS やフリーソフトウェアを使用していると、最後の砦はベンダーではなく自分たちになるので、コミュニティとの接点がとても重要と感じました。
RDBMSのアーキテクチャ
- データファイルは RDBMS ごとにデータフォーマットが違う
- ログは RDBMS で差はないです
- データファイルの I/O の最小単位は 8 KB
SQL実行のしくみ
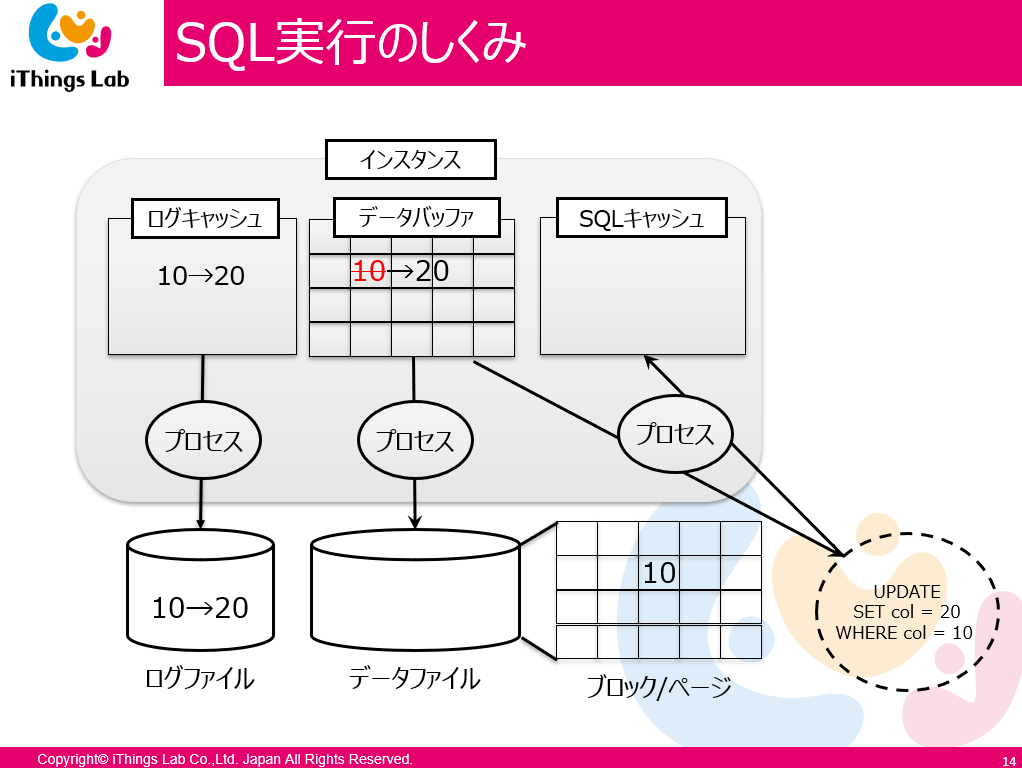
- ワーカープロセスが動く
- 解析(コンパイル)する
- 実行計画を最適化する // 全件 or インデックス
- 実行する
- まずデータバッファを探す on キャッシュ
- 無ければ、ディスクを見に行く
- ディスクから取る
- シーケンシャルサーチで連続したブロック、 1 エクステント (だいたい 64 KB ) を取りに行く
SELECT * FROM CUST WHERE id = 123;- SELECT と同じ動きで 123 をメモリにロードする
- 該当のレコードをロック
- ( Oracle ) ログバッファに変更前( = 10 )と変更後( = 20 )の値を書き込み
- 他 RDBMSの場合、SQL文を保持する (そのときに AND で変更前のデータを残して DELETE するものまで含んでいる)
- UNDO データを生成し保持
- ROLLBACK できるように
- データを更新する
- コミットする
- LGWR (Log Writer)
- 実はログバッファに書き込んでいる
- ディスクに書き込んでない
- 「え,障害を起こったらメモリにあがっているものが消えちゃうじゃない?」
- 実は再起動したときにディスクのタイムスタンプとログファイルのタイムスタンプを見て、差分を書き込んでいる
- (いつディスクに書くのか) DBWR が自動で 3 秒に 1 回書いている
- なぜ自動で?
- 空きバッファが無くならないようにやっている
- どういうこと?
- メモリ <-> ディスク の差分を確認
- 値が一致 -> 空きバッファとみなして使う
- 値が不一致 <-> 使用済みバッファとして使わない
- それでも空きバッファが埋まる
- メモリ <-> ディスク の差分を確認
- DBWR がコミットしてない場合でもディスクに書く
- 同時にログバッファに DBWR 前のデータを書く
- なぜ自動で?
UPDATE emp SET sal = sal*2 WHERE id = 123;こういうアーキテクチャを知ると、ログファイルはとっても大事ですね。
障害の種類の原因と対応
今までセキュリティやパフォーマンスを中心にしてきましたが、ここからはその他の障害を取り上げます。
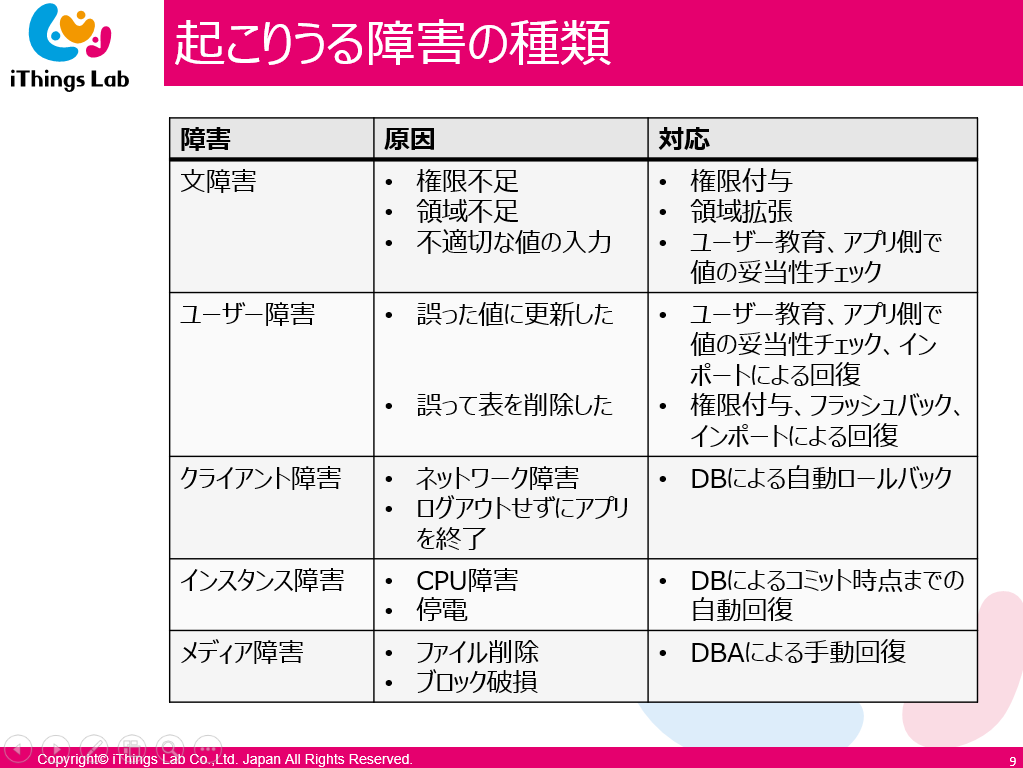
- リカバリ方法が RDBMS によって違う
- 例えばブロックで障害が起こったら、Oracle や SQL Server ならブロックだけをリカバリする
- 他の RBMS は全部リストアする
- クライアント障害
- トランザクション処理が途中で止まって障害になること
- RDBMS が勝手にロールバック復旧するので対策しておかなくてよい
- ユーザー障害
- 誤った操作で書き込んでしまった
- 多分ユーザーが改めて書き込む -> 対策必要ない
- 誤って削除した
- 対策は論理バックアップしておく (エクスポート・インポートで回復)
- でも慣れた方法が良いので、 SQL 文でレコードを保存しておいたほうがよいですよ
- 誤った操作で書き込んでしまった
参考
バックアップの SQL は下のように書くのがオススメです、ということで紹介頂きました。
CREATE TABLE emp2 AS SELECT * FROM EMP;INSRET INTO emp
SELECT * FROM emp2
WHERE ID = hoge;メディア障害
- ログファイル
- ( Oracle の場合) LGWRはログファイルがいっぱいになったら切り替えてる
- このタイミングで CKPT( CheckPoint ) を作成
- ここでディスクにログファイル内容を書き込む
- もし更新せずに永続化したいときはそのように設定しましょう
- ログバックアップが取るように設定しましょう
- そうするとファイルを切り替えたタイミングでアーカイブを作っている
- ( SQL Server の場合) ログファイルがいっぱいになったら拡張している
- この場合、バックアップは時間単位 (間隔) でやっている
- なのでログファイルは冗長化するよう設定しましょう
- ( Oracle の場合) LGWRはログファイルがいっぱいになったら切り替えてる
バックアップとリカバリ
バックアップ
- DB を止めて バックアップするということは難しい
- なぜ止めたいのか?
- DB は 8 KB 単位でブロックに書き込む
- OS は書き込む単位が違う
- DB と OS との差分が発生する
- なので、
begin backupのようなコマンドを打って、タイムスタンプつきでその差分をログファイルに書き込んで、その間の差分も持つようにしているend backupで止めることも忘れずに
- これがオンラインバックアップ
- なぜ止めたいのか?
- RDBMS ごとに ↑ をまとめたバックアップコマンドがある
復旧 (リカバリ)
復旧には大きく分けて 2 つのやり方がある
- リストア
- バックアップデータで復元する
- リカバリ
- ログファイルなどを使ってバックアップからの差分も回復する
- バックアップデータより過去に戻ってしまうこともある (?)
バックアップデータより過去に戻ってしまうこともある (?)
なぜ、それが起こるのか、解説いただきました。
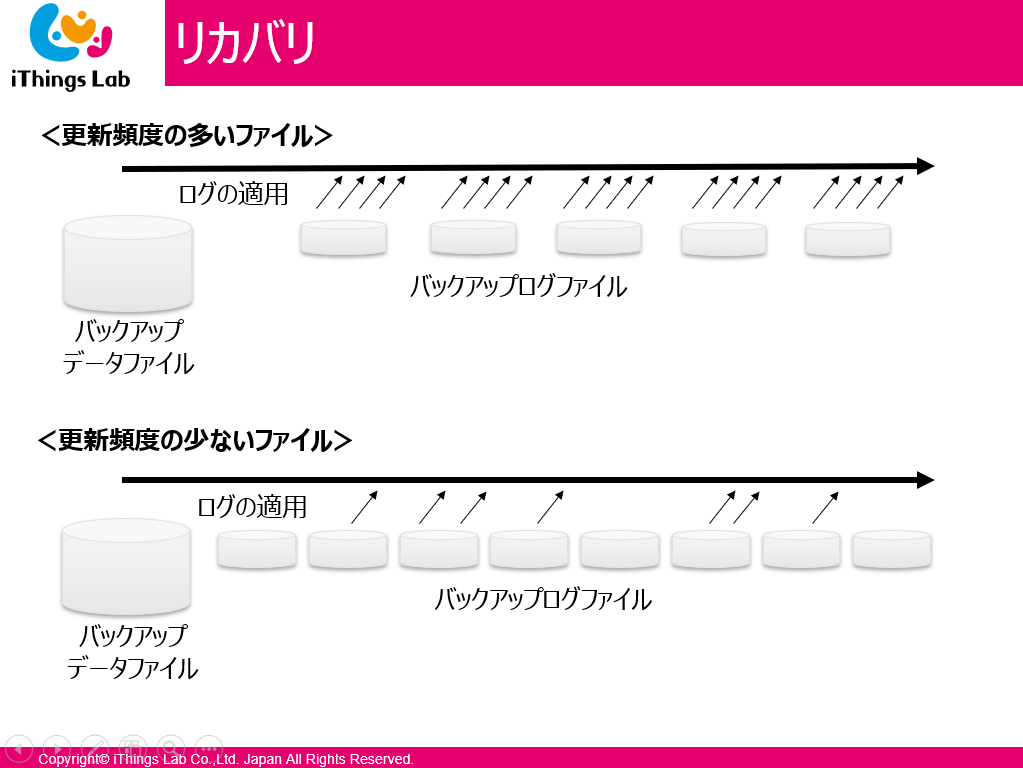
ログの適用のタイミングによって、生成されたバックアップより過去に戻ってしまうことがあることが理解できました。
ここまで解説頂いたところで、残念ながら、タイムアップとなりました。
まとめ
データベースで発生する障害のパターンと林さんの経験上、障害とも言えるセキュリティやパフォーマンスについても、その原因と対応策を解説いただきました。
特にRDBMSのアーキテクチャを交えて、わかりやすく解説頂けたので、例えば、ログファイルがなぜ重要なのか気づけました。
一方、そのアーキテクチャを厚く説明頂いたので、逆に演習時間が無くなってしまったのが残念でした。なかなか講座のバランスは難しいですね。林さんからもお詫びと、次回はしっかりと演習時間を確保することをコミットしてらっしゃったので、今後はブラッシュアップした内容になりそうです。
トラブルシュートはアプリケーションの性質や DBMS のアーキテクチャまで幅広くケアするものになるので、 DBA の総仕上げとも言えそうです。 DBA として一人前になるという方にはとてもオススメの内容でした !
SEプラスにしかないコンテンツや、研修サービスの運営情報を発信しています。