Python で業務を自動化しよう ~ファイル操作から Excel まで~|研修コースに参加してみた

今回参加したコースは Python で業務を自動化しよう~ファイル操作から Excel まで~ です。
仕事でコンピュータを使うときには、単純作業を繰り返すことがよくあります。 たとえば、条件にあうデータを探してコピーしたり、いくつもの Excel ファイルを開いてコピーしたりといったことです。
そういった作業は Python で自動化して効率的に済ませてしまいましょう。 Python なら仕事を効率化するプログラムを短いコードで記述できます。
このコースは、複雑な定例業務でも自動化したいと思っている人に向けて、 Python によるファイル操作や Excel ファイルの操作などを解説します。 また Python プログラミングを始めたばかりの方には、プログラミングに慣れる、うってつけの材料でした。
では、どんなコースだったのか、レポートします!
もくじ
コース情報
| 想定している受講者 | Python の基本文法を理解している |
|---|---|
| 受講目標 | ファイル操作や Excel ファイルからのデータ読み込みという、多くの職場で応用できる技術を習得する |
講師紹介
この “参加してみた” レポートでは初めての登場となる 廣瀬 豪さんが登壇されました。
ゲーム制作をはじめとしたプログラミング技術をやさしく・楽しく教えるベテラン講師
早稲田大学理工学部卒。 ワールドワイドソフトウェア(有)取締役。 ナムコでプランナー、任天堂とコナミの合弁会社でプログラマーとディレクターを務めた後に独立。
携帯電話や家庭用ゲーム機向けに 100 タイトル以上の公式アプリを開発、総ダウンロード数は 2000 万ダウンロードを超える。
会社経営のかたわら、教育機関でプログラミングを指導したり、本を執筆している。
プログラミング歴は約 40 年で、 C / C++ 、 Java 、 JavaScript 、 Python など多くの言語を使いこなす。
-
主な著書
- いちばんやさしい Java 入門教室(ソーテック社 刊)
- Python でつくる ゲーム開発 入門講座(ソーテック社 刊)
- Python で学ぶ アルゴリズムの教科書(インプレス 刊)
- 野田クリスタルのこんなゲームが作りたい! Scratch3.0 対応(共著 インプレス 刊)
- 7 大ゲームの作り方を完全マスター! ゲームアルゴリズムまるごと図鑑(技術評論社 刊)
など著書多数
早速、コースがスタートし、業務の自動化の現状を紹介いただきました。
- 自動化ができるノーコード/ローコードツールが広がる
- 廣瀬さんも実際使ってみたが、高度な自動化にはプログラミングの基礎が必要と感じた
- 変数や分岐、繰り返しなどの知識
- Python を使えば、手早く自動化プログラムを書ける
ここからはその業務の自動化でよく使う処理、ファイル操作、テキストファイルや文字列操作、 Excel や CSV の操作を取り上げ、仕上げとして最後に様々な自動化プログラムを紹介いただきました。
なお、このコースは Python の基本文法、制御構文や print() などよく使う関数を知っていることが前提で進みます。 また、開発環境は Python 3 で、私はクラウド IDE の JupyterLab を使いました。
Python でのファイル処理 shutil と os ライブラリを使ってみよう
では、基本となるファイル処理をやってみましょう。 コースでは使用するファイルを格納したフォルダが用意されていました。
フォルダ内のファイルのコピー
ファイルの操作には shutil というライブラリを使用します。
import shutil
ORIGINAL = "コピー元"
NEWFOLDER = "コピー先"
shutil.copytree(ORIGINAL, NEWFOLDER)“コピー元” というフォルダと格納されているファイルが、新しくできた “コピー先” というフォルダにすべてコピーされました。
フォルダの作成
フォルダの操作には os というライブラリを使用します。
import os
FOLDER = "新しいフォルダ"
if not os.path.exists(FOLDER): # フォルダの存在チェック
os.mkdir(FOLDER)
else:
print("フォルダが既に存在します")
フォルダ内のファイルを調べて表示する
引き続き、その os ライブラリを使って、フォルダにあるファイルをすべて表示します。
import os
FOLDER = "コピー元"
for f in os.listdir(FOLDER): # listdir() で引数のフォルダにあるフォルダとファイルをすべて取得
print(f)フォルダ内のフォルダ
ワード文書2.docx
テキストファイル.txt
エクセルデータ.xlsx
画像.png
ワード文書.docx特定の拡張子のファイルだけコピーする
os と shutil の両方のライブラリとこれまでに使った関数を組み合わせて、特定のファイルをコピーします。 ここでは Word が対象です。
import os
import shutil
FOLDER = "ワード文書だけ保存"
if not os.path.exists(FOLDER):
os.mkdir(FOLDER)
ORIGINAL = "コピー元"
for f in os.listdir(ORIGINAL):
if f.endswith(".docx"): # endwith() で文字列の終わりを調べる
shutil.copy(ORIGINAL + "/" + f, FOLDER + "/" + f) # コピー元/ファイル を ワード文書だけ保存/ファイル にコピー
print(f, "をコピーしました")実行してみましょう!
ワード文書2.docx をコピーしました
ワード文書.docx をコピーしました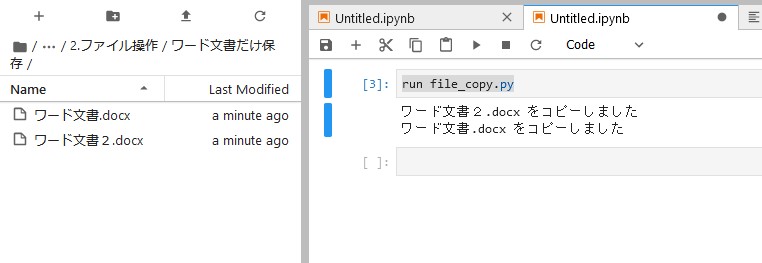
自動化するときは、フォルダとファイル操作は必須ですが、だいたいのことはこれでできますね。 また、同様のことはシェルスクリプトでもよくやりますが、それよりわかりいいです。
テキストデータの処理
操作したいファイルを抜き出したところで、今度はそのファイルにある情報を読んだり書いたりします。
- テキストデータの処理にライブラリは不要で標準ライブラリを使えば OK
- open() と close() と read() と write() をよく使う
- 文字コードに注意
- Shift-JIS と UTF-8
最後の文字コードは本当に厄介です。 UTF-8 で統一できない … ですよねぇ。
ファイルを読み込んで見る
では、ファイルの中身を呼んでみましょう。
f = open("予定表.txt", 'r', encoding = "UTF-8")
txt = f.read()
f.close()
print(txt)- 引数 1: 開きたいファイル
- 引数 2:
'r'オプションで読み込みを指定 - 引数 3: エンコーディングを指定
2022年4月〇日 講座A
2022年5月〇日 講座B
2022年6月〇日 講座A
2022年7月〇日 講座B
2022年8月〇日 講座A
2022年9月〇日 講座Bでは、文字コードが混在しているときにはどうするのでしょうか。
try:
f = open("予定表2.txt", 'r', encoding = "utf_8")
txt = f.read()
except:
print("Shift-JIS形式のファイルです")
f = open("予定表2.txt", 'r', encoding = "Shift-JIS")
txt = f.read()
f.close() # with open() as f: を使うと省略できる
print(txt)Shift-JIS形式のファイルです
2022年4月〇日 講座A
2022年5月〇日 講座B
2022年6月〇日 講座A
2022年7月〇日 講座B
2022年8月〇日 講座A
2022年9月〇日 講座B
※SHIFT-JIS(ANSI)で保存されたファイルなるほど、例外処理を使えば、なんてことはなく片付きますね。
読み込んだデータをリストにする
先程はそのまま読み取ったテキストをそのまま出力しましたが、それをリスト(配列)にして後で処理しやすくできます。
f = open("予定表.txt", 'r', encoding = "UTF-8")
txt = f.readlines() # readlines() で読んでリストにする
f.close()
print(txt)['2022年4月〇日\u3000講座A\n', '2022年5月〇日\u3000講座B\n', '2022年6月〇日\u3000講座A\n', '2022年7月〇日\u3000講座B\n', '2022年8月〇日\u3000講座A\n', '2022年9月〇日\u3000講座B']ただし余計な改行コード '\n' が入ってしまっています( '\u3000' は全角スペースを表す文字コードなのでこれはそのままで OK )。
これを除きましょう。
- 特定のキーワードでリストを分割する
- split() を使う
f = open("予定表.txt", 'r', encoding = "UTF-8") txt = f.read() f.close() ary = txt.split("\n") # 改行コードで分割 print(ary)
['2022年4月〇日\u3000講座A', '2022年5月〇日\u3000講座B', '2022年6月〇日\u3000講座A', '2022年7月〇日\u3000講座B', '2022年8月〇日\u3000講座A', '2022年9月〇日\u3000講座B']新規にテキストファイルを保存
これまではファイルの中身を読む処理でしたが、今度は書き込みをしてみましょう。
f = open("新規ファイル.txt", 'w', encoding = "UTF-8") # w オプションで書き込みを指定して "新規ファイル" を作成
for i in range(20):
f.write(str(i) + "行\n") # str() は引数を文字列に変換
f.close()
0行
1行
(中略)
18行
19行文字列操作
ファイルの中身、文字列を編集してみましょう。
- 文字列の操作には replace() を使う( str 型の関数)
- 他によく使う大文字小文字の変換には upper() / lower() を使う
- 文字列の検索やカウントには find() / count() を使う
ここで使用する 旧文書.txt の中身はこちらです。
①朝礼
②午前の業務
③昼休み
④午後の業務
⑤業務報告この環境既存する丸括弧の SHIFT-JIS の文字を変換し、先程の書き込み処理を加え、新文書.txt を作ります。
OLD = ["①", "②", "③", "④", "⑤"]
NEW = ["(1)", "(2)", "(3)", "(4)", "(5)"]
with open("旧文書.txt", 'r', encoding = "shift_jisx0213") as f: # テキストでは encoding = "ANSI" でしたが decode error になったため変更
txt = f.read()
for i in range(5):
txt = txt.replace(OLD[i], NEW[i]) # OLD から要素を 1 つずつ取り出して NEW の要素に書き換える
with open("新文書.txt", 'w', encoding = "UTF-8") as f:
f.write(txt)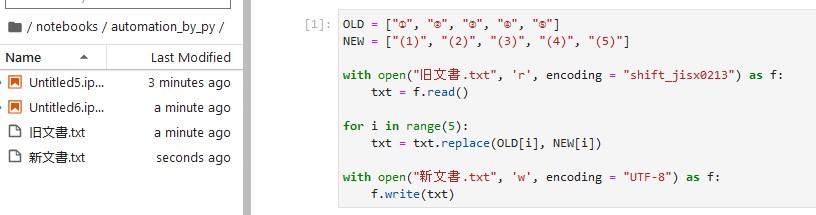
(1)朝礼
(2)午前の業務
(3)昼休み
(4)午後の業務
(5)業務報告コースでは他に upper() や lower() についても試してみました。
エクセルや CSV のデータを読む
業務の自動化で使うファイルといえば、 Excel や CSV です。 自動化で一番やりたいことですね。
まずは CSV を扱いましょう。
csv ライブラリで CSV ファイルのデータを読み取る
まずは CSV ファイルのデータを読んでみましょう。
import csv
f = open("Book1.csv", 'r', encoding = "UTF-8") # "UTF 8 sig" を指定すると、 list のヘッダの \ufeff という BOM を取り除ける
cr = csv.reader(f) # ファイルを読み込みオブジェクトにする
txt = list(cr) # list() の引数はオブジェクトでリストにする
f.close()
for i in txt: print(i)['\ufeff氏名', '住所', '電話番号']
['廣瀬 豪', '〒111-1111 栃木県〇〇市電脳町2', '080-1111-1111']
['山田 花子', '〒222-2222 東京都〇〇区末広町888', '090-2222-2222']
['佐藤 太郎', '〒333-3333 北海道札幌市〇〇777', '070-3333-3333']CSV ファイルに書き込む
今度は書き込んでみましょう。
- writer() でオブジェクトを生成して、 writerows() で二次元リストを書き込む
- writerow() なら一次元リストを書き込む
import csv data = [ ["氏名1", "生年月日1", "TEL1", "住所1"], ["氏名2", "生年月日2", "TEL2", "住所2"], ["氏名3", "生年月日3", "TEL3", "住所3"] ] f = open("Book_new.csv", 'w', newline='') cw = csv.writer(f) cw.writerows(data) f.close() print("cvsファイルに書き込みました") - open() の引数に newline をつけると、生成したファイルを Excel で開いた際、余計な空行が入らない
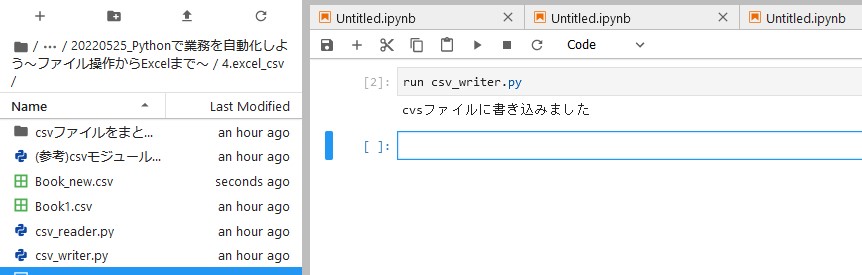
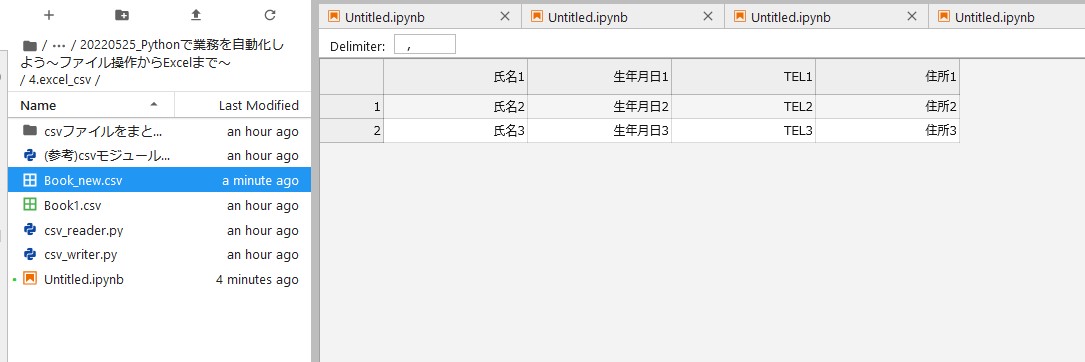
このあと、 CSV ファイルをもとに、これまでのファイル操作と CSV の操作を組み合わせたプログラムも試してみました。
エクセルデータを使う openpyxl ライブラリを使う
今度は本命の Excel です。
- openpyxl を使う
- 外部ライブラリなので、 pip インストールが必要
$ pip3 install openpyxl # JupyterLab の場合は !pip3 install --upgrade openpyxl Collecting openpyxl Downloading openpyxl-3.0.10-py2.py3-none-any.whl (242 kB) |████████████████████████████████| 242 kB 4.7 MB/s eta 0:00:01 Collecting et-xmlfile Downloading et_xmlfile-1.1.0-py3-none-any.whl (4.7 kB) Installing collected packages: et-xmlfile, openpyxl Successfully installed et-xmlfile-1.1.0 openpyxl-3.0.10
Excel ファイルのデータを読み取る
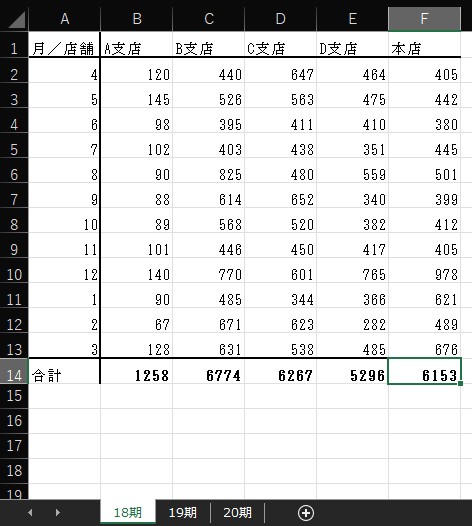
読み取る Excel ファイルのデータは以下のようなものです。
import openpyxl
wb = openpyxl.load_workbook("過去3年度分の売上.xlsx") # Excel ファイルを読み込み(オブジェクト)
SHEET = 0 # シートを指定
sh = wb[wb.sheetnames[SHEET]] # wb.sheetnames でファイルのシート名をすべて取得し、先頭のシートを取得
add = 0
print(wb.sheetnames, len(wb.sheetnames)) # len() でシート名の配列から要素数を出力
print("シート", SHEET + 1, "行数", sh.max_row)
print("シート", SHEET + 1, "列数", sh.max_column)
# 二重ループで行と列の値を出力。 1 行ごとに複数列の値を出力し合計
for y in range(1, sh.max_row): # max_row で最終行まで繰り返し
for x in range(1, sh.max_column + 1): # sh.max_column + 1 で最終列まで繰り返し
print(sh.cell(y, x).value, end = ",") # sh.cell(y, x).value でセルの値を取得
if y > 1 and x > 1: add += sh.cell(y, x).value # 変数 add に取得した値を加算
print("\n----------------------------")
print("合計額", add)['18期', '19期', '20期'] 3
シート 1 行数 14
シート 1 列数 6
月/店舗,A支店,B支店,C支店,D支店,本店,
----------------------------
4,120,440,647,464,405,
----------------------------
5,145,526,563,475,442,
----------------------------
6,98,395,411,410,380,
----------------------------
7,102,403,438,351,445,
----------------------------
8,90,825,480,559,501,
----------------------------
9,88,614,652,340,399,
----------------------------
10,89,568,520,382,412,
----------------------------
11,101,446,450,417,405,
----------------------------
12,140,770,601,765,978,
----------------------------
1,90,485,344,366,621,
----------------------------
2,67,671,623,282,489,
----------------------------
3,128,631,538,485,676,
----------------------------
合計額 25748今回は先頭のシートだけを行いましたが、 SHEET をループすると、すべてのシートをまとめて処理できます。
廣瀬さんからは openpyxl にはクセがあり、 wb[wb.sheetnames[SHEET]] などの書き方や、行と列が 1 から始まるところなどを注意いただきました。 教えてもらわないとハマってしまうところですね。
コースではこのあと openpyxl の BarChart() を使ってグラフを描きました。 クセはあっても万能すぎるライブラリです。 同じような自動化は Google App Script ( GAS ) でもできますが、ライブラリの豊富さが断然違いますね。
様々な自動化処理
今まで学んだことをもとに、様々な自動化に取り組んでみます。 廣瀬さんから以下のような自動化を挙げられました。
- Python で日時を扱う
- 決められた時間になったら、何らかのプログラムを起動する
- インターネットからデータを自動収集する(スクレイピング)
- ワード文書を読み込む
- メールの自動送信
- クライアントからサーバへデータを送信する( Web への転記の基礎)
いずれも使いたい処理ばかりですね!
コースではこの中から複数試してみましたが、このレポートではスクレイピングを取り上げます。
Python でスクレイピング
スクレイピングができる標準ライブラリは無いので、 requests ライブラリをインストールします。
$ pip3 install requests # !pip3 install --upgrade requests
Requirement already satisfied: requests in /srv/conda/envs/notebook/lib/python3.7/site-packages (2.26.0)
Collecting requests
Downloading requests-2.27.1-py2.py3-none-any.whl (63 kB)
|████████████████████████████████| 63 kB 1.9 MB/s eta 0:00:011
# 中略
Successfully installed requests-2.27.1ただし、スクレイピングは拒否しているサイトも多いので注意が必要です。 今回は廣瀬さんの会社ホームページ https://www.wwsft.com/ で試してみます。
import requests
url = "https://www.wwsft.com/"
html = requests.get(url) # ページを取得
html.encoding = html.apparent_encoding # 重要!! 文字化けの解消
print(html.text)- apparent_encoding なしで
print(html.encoring)とすると ISO-8859-1 と判定していた
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<meta name="description" content="ゲームクリエイターを目指す方を支援します">
<meta name="keywords" content="Python,JavaScript,Scratch,C#,Java,プログラミング,ゲーム開発">
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=10.0, user-scalable=yes">
<link rel="stylesheet" href="style.css" type="text/css">
<title>ワールドワイドソフトウェア</title>
# 中略
<footer><p><small>©WorldWideSoftware</small></p></footer>
</body>
</html>無事に取得できました! ラクすぎる!
画像のみをスクレイピング
さらに、応用して先程の廣瀬さんの会社ホームページから画像のみを取得してみましょう!
import requests
import time
url = "https://www.wwsft.com/"
html = requests.get(url)
html.encoding = html.apparent_encoding
cnt = 0
pos = 0
while True:
p = html.text.find("img src=", pos) # 画像の位置を習得
if p == -1 : break # img src= の存在チェック ≒ 画像の存在チェック
n = html.text.find(".png", p + 1) # 取得した位置から .png が始まる位置を取得
if n > 0:
img_url = url + html.text[p + 9: n] + ".png" # 画像のパスを生成
img = requests.get(img_url).content # 画像ファイルを取得
print(img_url)
with open("image" + str(cnt).zfill(3) + ".png", "wb") as f: # 画像ファイルを生成
f.write(img)
cnt += 1
time.sleep(1)
pos = p + 1- 見つかった場合は最初の位置を返す
- 見つからなかった場合は -1 を返す
- 2 つめの引数で開始位置を指定
https://www.wwsft.com/img/wws.png
# 中略
https://www.wwsft.com/img/bn_sotech.png
まだまだ未熟な私からすると find() の使い方に目が覚める思いでした!
最後の画像のスクレイピングが終わったところで、このコースは修了しました。
まとめ
Python で業務を自動化するときによく使う、ファイル操作、テキスト操作、 Excel / CSV の操作するプログラムを中心に解説いただき、最後には様々な自動化を試してみました。
Python は「短いプログラムで書ける」とはよく聞きますが、本当に短く書けて、直感的に何をしているのかがわかりやすかったです! また使えるライブラリが豊富なことも魅力的でした。
またプログラミングにまだ慣れない私には、 while の使い方やパスなどの記述、様々な書き方がとても刺激的でした。 これは練習台として取り組むのに非常に良いですね!
ノーコード/ローコードによる自動化では満足できない方や、私のように Python プログラミングにもっと慣れたいという方には、とてもオススメのコースでした!
label SEカレッジを詳しく知りたいという方はこちらから !!
IT専門の定額制研修 月額 28,000 円 ~/ 1社 で IT研修 制度を導入できます。
年間 670 講座をほぼ毎日開催中!!
SEプラスにしかないコンテンツや、研修サービスの運営情報を発信しています。