Python で 機械学習 入門 研修コースに参加してみた

今回参加した研修コースは Python で機械学習入門 です。
SEカレッジでも AI、機械学習、深層学習などのコースが開催されるようになりましたが、いずれも人気です。このコースも満員御礼です!
以前に AzureML でマウスでポチポチしながら機械学習の流れを学ぶコースをレポートしましたが、このコースでは実際に Python を使って学習モデルを作るのを体験するコースでした。

研修コースに参加してみた
そして、このコースの特徴的な点が、サンプルコードをもとに、それを実行していくだけで、Python をあまり知らなくても、どのような統計手法と Python のライブラリを使えばよいのか、それがわかるコースでした! (わかった気になってる)
ちなみに、弊社の製品にも機械学習を適用できるヒントをつかめました!
では、どのような内容だったのか、レポートします!!
もくじ
コース情報
| 想定している受講者 |
|
|---|---|
| 受講目標 | Python を使って簡単な学習モデルを作るまでの流れがわかる |
講師紹介
プログラミングカテゴリでは最多登場となる 米山 学 さんです。

JavaはもちろんPython/PHPなどスクリプト言語、Vue/ReactなどJSだってなんだってテックが大好き。原点をおさえた実践演習で人気
米山さんの講座では Dropbox Paper で講座のドキュメントを用意され、受講者とはブラウザで共有するのですが、とてもコードが共有しやすく、先読みも振り返りもしやすいので、とても重宝しています。
ここでは公開できないので、ぜひ講座を受講して体験ください。
今日の環境
データ分析の流れと、そこで使う代表的なライブラリを実際にチュートリアルでやってみます
- Anaconda を使う
- OSS
- データサイエンスに関わるすべてのものを1つに集まっている
- 今日使うデータセットも含め、必要なものすべてがインクルードされている
- 統合開発環境のようなもの
- 特に Windows は環境構築でハマりがち
- ライブラリで特にコケる
- Python 以外に R なども用意されている
- Jupyter Notebook を使う
- ブラウザベース
- REPLのような実行環境
- 実行結果のグラフなどもその場で表示できる
- 今日のデータセット
- iris (花のアヤメ) のデータセット
- https://archive.ics.uci.edu/ml/datasets/iris
- 50 件しか無い
- 使うときはカラム名をつけるのを忘れずに
Anaconda はバリバリやる人には不評ですが、初学者にはとてもやさしいですね。
ただ重いので、Miniconda でも同じようなことが出来るのかなぁ、と気になっています。
機械学習やデータサイエンスとは
簡単にデータサイエンスという言葉が何を意味しているのか、サッと解説されました。
- 様々なデータを統計解析して予測したり、未知の値を分類したりする
- 機械学習 Machine Learning -> Deep Learning がでてきた
- Python がよく使われる理由
- 統計解析で使うライブラリが豊富にある
前準備
まずデータセットを読み込めるよう準備します。
- Pandas を使う
- データ操作を行うライブラリ
- iris.data のラベル付け
- SepalLength, SepalWidth, PetalLength, PetalWidth, Class
- iris.data の読み込み
# 品種ごとにデータを区分け setosa = iris[iris["Class"] == "Iris-setosa"] versicolor = iris[iris["Class"] == "Iris-versicolor"] virginica = iris[iris["Class"] == "Iris-virginica"]
通常何かを表示する場合、print() を使いますが、Jupyter Notebook は変数名の入力だけで表示されます。
基本要約統計量でどんなデータなのか把握する
どんな特徴をもつデータなのか、対象外のデータはどれぐらいありそうなのか、などなど確認します。
- 要約統計量 ・・・平均値や合計値など
#要約統計量の表示 setosa.sum() # 合計 setosa.min() # 最小値 setosa.max() # 最大値 setosa.mean() # 平均値
ピボットテーブル (クロス集計) の作成
- ex. 各品種ごとの平均を算出
- pd.pivot_table(第1引数, 第2引数, 第3引数)
import numpy as np pd.pivot_table(iris, index="Class", aggfunc=np.mean)arrow_downward実行
Class PetalLength PetalWidth SepalLength SepalWidth Iris-setosa 1.464 0.244 5.006 3.418 Iris-versicolor 4.260 1.326 5.936 2.770 Iris-virginica 5.552 2.026 6.588 2.974 - NumPy が提供している定数 aggfunc を使う
- NumPy を使って Pandas が作られている
- NumPy と Pandas はめちゃくちゃ使う // 必須
- ヒストグラムの描画
- ある値を持つデータがどれだけあるのか確認する
- x が値, yが度数
- だいたい度数が高くなるのは平均値
- 平均値を中心に山型になることを正規曲線分布という
- キレイな山にならない場合は値のばらつきなども確認できる
- グラフの描画ができるライブラリ Matplotlib
- 巨大なので目的に応じたサブライブラリを指定する
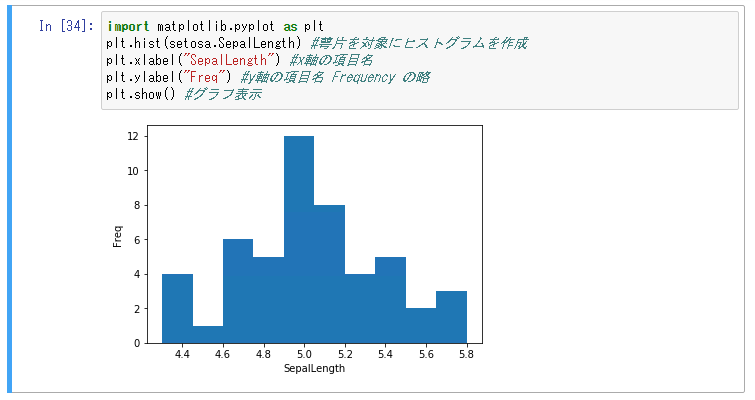
import matplotlib.pyplot as plt plt.hist(setosa.SepalLength) #萼片を対象にヒストグラムを作成 plt.xlabel("SepalLength") #x軸の項目名 plt.ylabel("Freq") #y軸の項目名 Frequency の略 plt.show() #グラフ表示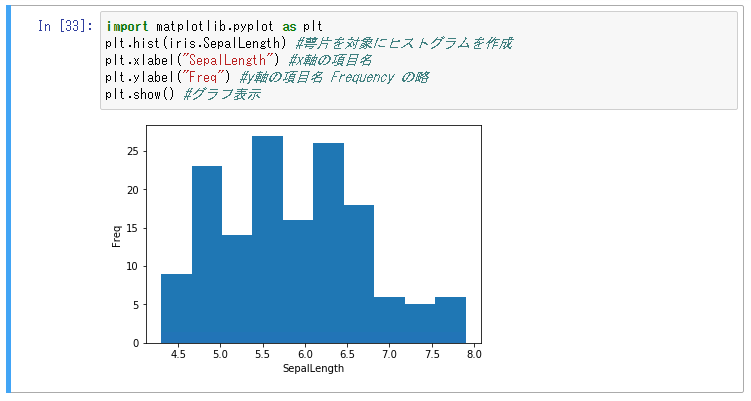
- 巨大なので目的に応じたサブライブラリを指定する
- 実行結果の解説
- グラフがいびつなのは iris 全体を指定しているから
- setosa を指定すると正規曲線になる
- いまは 50 しかないので、ばらつきがでる -> 1000以上は必要 -> データがあればあるほどよい
四分位数と箱ひげ図
- データを4つの箱に区切り、真ん中2つを対象とする
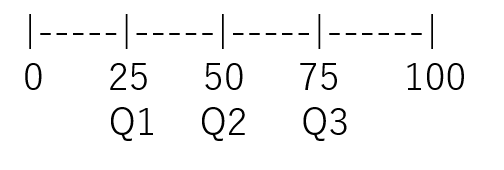
- Q1 から Q3 を四分範囲という
- 四分範囲から 1.5 倍した両端の値から外れたものは外れ値として解析対象ではなくなる
- 株価とかでよくつかう
# 箱ひげ図の描画
# 品種ごとに萼片の長さを見比べる
data = [setosa.SepalLength, versicolor.SepalLength, virginica.SepalLength]
plt.boxplot(data) # 箱ひげ図の描画 boxplot()
plt.xlabel("Class") # x軸名
plt.ylabel("SepalLength") # y軸名
# 各品種のラベル
plt.setp(plt.gca(), xlabel=["setosa", "versicolor", "virginica"]) # ラベル付けは setp()
plt.show()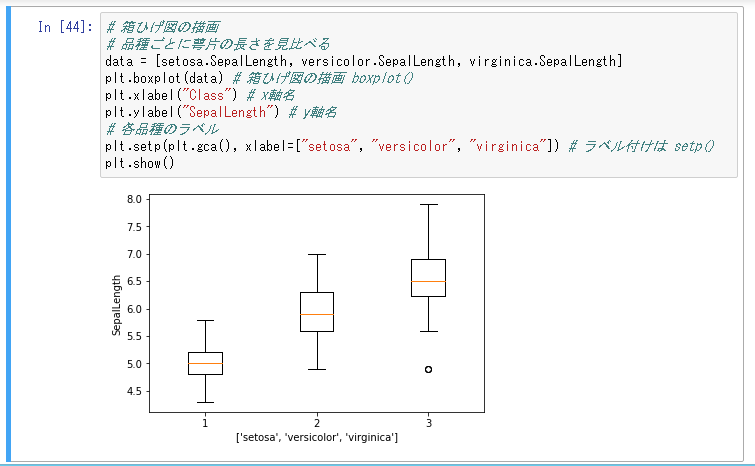
機械学習で学習モデルを作る
データの特徴がわかったところで、そのデータを使って学習モデルを作ります。
まずは学習モデルを作るにあたって、機械学習を行う上で2つの目的があることを説明いただきました。
- 未知の値を予測する
- 相関分析
- 2つのデータ (二変量) に関連があるかどうか調べる
- どれぐらい関係があるのか数値でわかる
- 相関係数と呼ばれる
- -1 <- 0 -> 1
- 0 だと関係がない
- 1だと正の相関関係がある
- -1 だと負の相関関係がある // ある値が上がれば相関する値が下がる
- x -> y になるかどうか
- 入力から出力が予測できるかどうか
- 2つのデータ (二変量) に関連があるかどうか調べる
- 回帰分析
- あとでやります
- 相関分析
- データを識別
相関分析
- 相関分析を correlationCefficent と言う
- 略して corrcoef
np.corrcoef(setosa.SepalLength, setosa.SepalWidth)
- 略して corrcoef
- 実行結果
array([[ 1. , 0.74678037], [ 0.74678037, 1. ]]) - 相関行列が出力される
x y x 1 0.7 y 0.7 1 - 結果の解説
- 0.6 が目安なので、萼片の長さと萼片の幅は相関がある
- 他 setosa.SepalLength, versicolor.PetalWidth でやってみると 0.08 が検出される (相関がない)
相関があったなら散布図
x と y に実際に値をプロットしてどれぐらい相関があるか見てみる、それが散布図です。
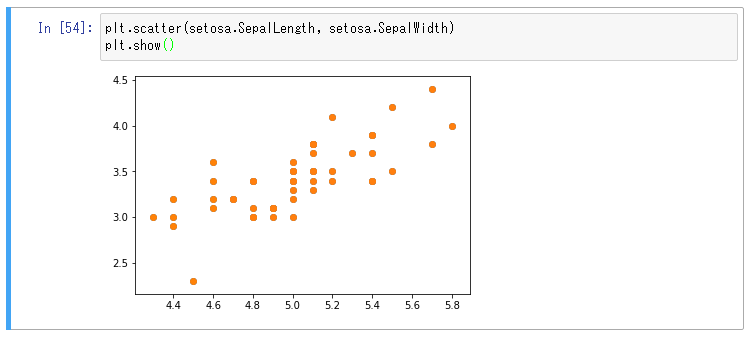
散布図の見方
- 相関がある = 因果関係がある という訳ではない
- 例えば 気温 と 水の事故 は相関があるが、因果関係があるかどうかは怪しい
- 因果関係は逆で考えるとわかりやすい
- 水の事故が多いから気温が高くなる?
- なので、相関があることがわかれば、因果関係があるかどうかを調べる
因果関係の分析に使うのが回帰分析
相関関係があると認められれば、今度は実際に予測値が導かれる式を求めます。
- 回帰分析
- y = a (x) + b になるのかどうかを分析する
- 直線と実際にプロットされたデータとの差を見る (残差)
- scikit-learn を使う
- 連続データを生成
- 等差数列という
- 直線が引けたら y = ax + b の a と b を求める
- a を ir.coef_ で求める
- b を ir.intercept_ で求める
- y = a (x) + b になるのかどうかを分析する
import sklearn.linear_model as lm
x = setosa[["SepalLength"]]
y = setosa[["SepalWidth"]]
ir = lm.LinearRegression() #回帰分析モデルの作成
ir.fit(x, y) #実際のデータを分析モデルに当てはめる
# 連続データの生成
px = np.arange(x.min(), x.max(), .01)[:, np.newaxis]
# 予測モデルの作成
py = ir.predict(px)
plt.plot(px, py, color='blue', linewidth=3) #値をプロット
plt.scatter(x, y, color='red')
plt.show()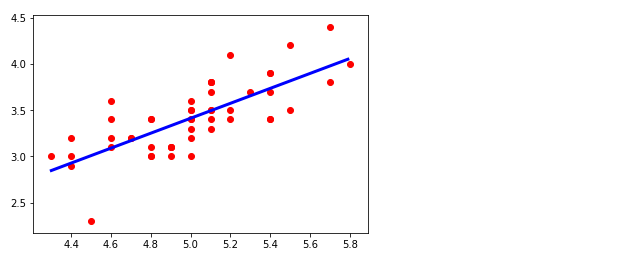
ir.coef_
array([[ 0.80723367]])
ir.intercept_
array([-0.62301173])実行結果により、y = ax + b の a と b がわかったところで、このコースは修了しました。
まとめ
このコースでは、Python のサンプルコードをもとに実際に動かしながら、学習モデルを作ってみました。
米山さんのコースはとても不思議で、あまり構文を知らなくても実際に動かしていると、実際に出来ている感覚 (成功体験のようなものだと思うのですが) がつかめるので、とても理解が進みました!
私にはとても刺激になったコースで、例えば、ある試験対策コースがあったとして、
- 受講者の合否結果と相関しそうな因子 (例えば修了率や正解率など) を様々に分析する
- たとえば相関分析で、相関がありそうなら散布図を使って検証する
- 相関関係があった因子と合否結果を回帰分析する
- その結果により、学習状況から合格率を予測する学習モデルができる
こんなアイデアが思い浮かびました。
(アイデアは検証可能になってはじめて価値があるので、ただの戯言です)
ということで作りたい意欲が高まるので、Pythonや機械学習未経験者の方には、とてもオススメです!!
label SE カレッジの無料見学、資料請求などお問い合わせはこちらから!!
label SEカレッジを詳しく知りたいという方はこちらから !!
IT専門の定額制研修 月額28,000円 ~/ 1社 で IT研修 制度を導入できます。
年間 670 講座をほぼ毎日開催中!!
SEプラスにしかないコンテンツや、研修サービスの運営情報を発信しています。