インデックス設計を見直してみよう 研修コースに参加してみた

今回参加した研修コースは インデックス設計を見直してみよう です。
インターネットで “インデックス設計” でググると、「やたらインデックスだらけになってしまう」という記事が多く見受けられます。
このコースでは、インデックス設計をおさらいしながら、色々なインデックスの種類を解説いただき、最後に実際 EXPLAIN しながらパフォーマンスを計測し、インデックスが効くのはどういうときか体験しました。
なかなかインデックス設計だけを集中して学べる研修コースは無いので、あやふやなので深掘りしたい、という方にはオススメのコースです!
では、どんな内容だったのかレポートします!
もくじ
想定している受講者
- データベース管理に関する用語が理解できている
受講目標
- 効果的なインデックスの設計および追加作成ができるようになる
講師紹介
データベース関連ではおなじみ 林 優子さん が登壇されました。いつものように、受講者の方が使っているRDBMSを調査してスタートです。
インデックス設計のおさらい
まずはインデックスをサラサラと復習します。
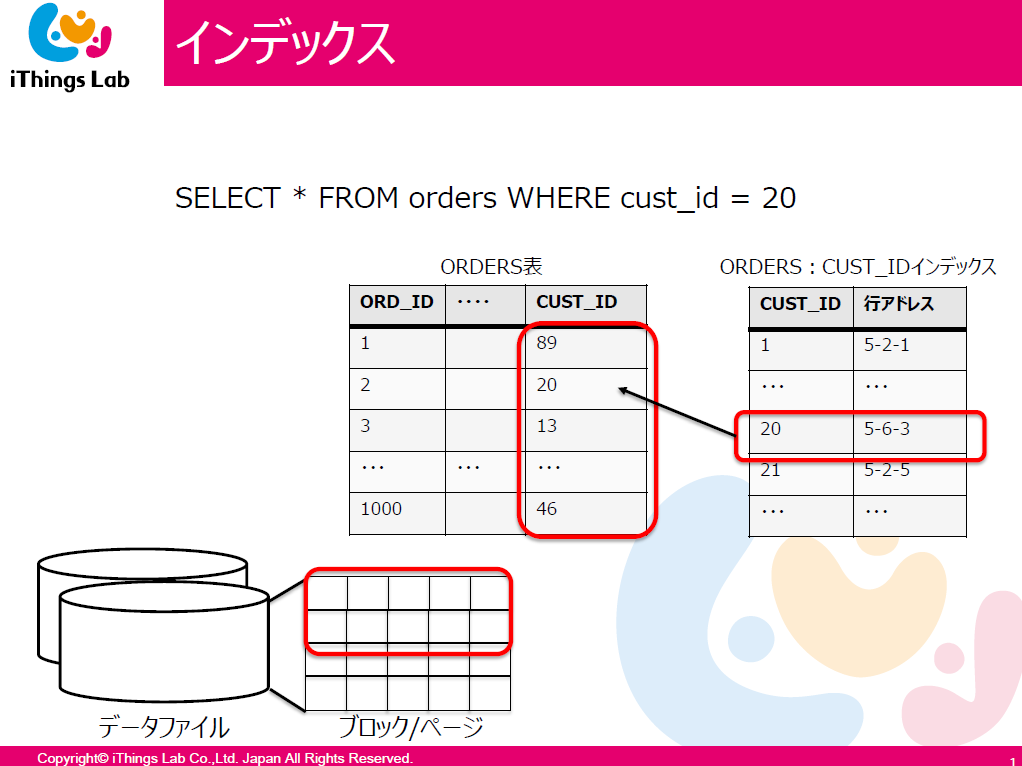
SELECT * FROM orders WHERE ORD_ID=2というとスグに見つかりますよねSELECT * FROM orders WHERE CUST_ID=2では、どうでしょう?- これが全件検索
- インデックスというオブジェクトを追加して行アドレスを指定する
- でも
CUST_ID=20と言われると結局、全件検索しますよね - それを避けるために BTree というアルゴリズムが使われている
- でも
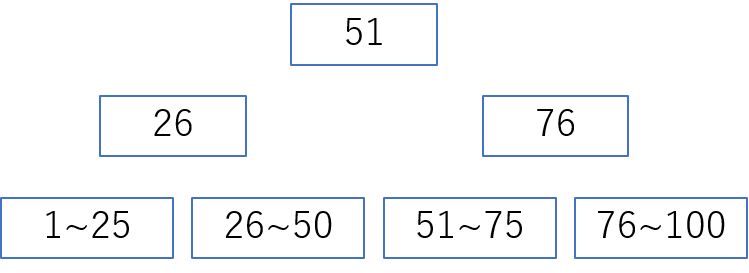
BTreeのイメージ
- テーブルのあるカラムに 1~100 のユニークな値が格納されているとする
- 47 という値を探し出すのに全件検索せず、47は51より下、47は26より上となり、 26~50 を探せばよい
RDBMSによる違い
- Oracleの場合
- リーフではなく直接テーブルになっている
- それ以外のRDBMSの場合
- クラスタ索引と呼ばれる
INSERTするときが違う- クラスタ索引はデフォルトはプライマリーキーに紐づく
- プライマリーキーではない値でもOK
- クラスタ索引はテーブルあたり1つ
-
クラスタ索引はテーブルの値を小さい順に並べるので、
INSERT時に並び替えの一手間が入る -
ランダムな値が格納されている場合は、
クラスタ索引を構成し直すので、時間がかかる - 夜間バッチで一括INSERTするときには、
索引を削除してから処理することが多い
- 夜間バッチで一括INSERTするときには、
いろいろなインデックス
RDBMSによって採用されている索引の種類が違うのですが、主な索引の種類を紹介いただきました。
なお、このあたりのインデックスは create index しないとアプライされないので、注意が必要です。
ビットマップインデックス
- AND で続く限り、索引でテーブルを作らない
- 遅い。。ので索引検索は苦手
- こういうときにビットマップインデックスが使える
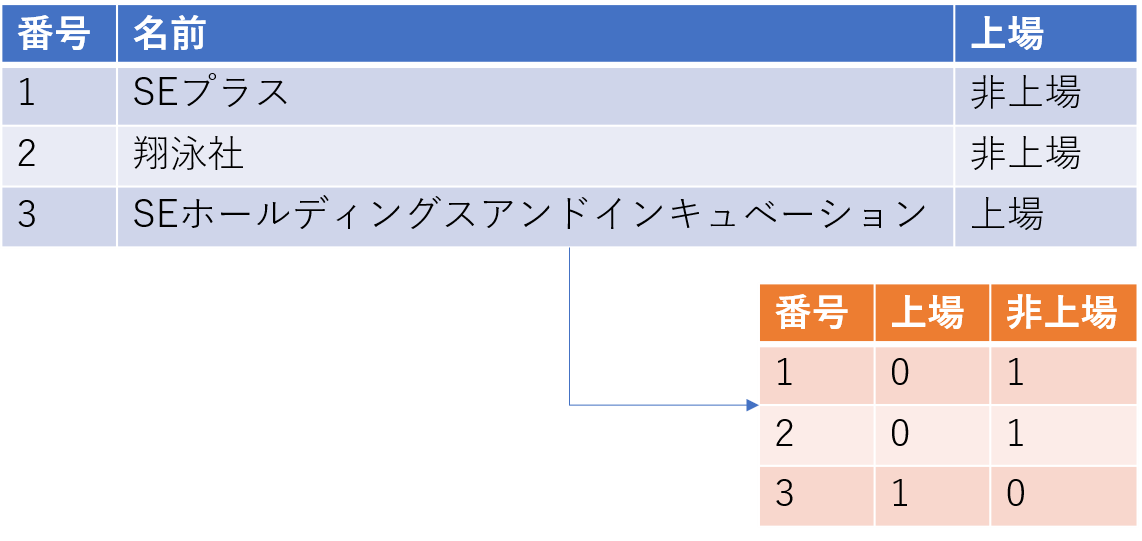
- リーフブロックごとに値があるかどうかを出している
- レコードごとに 上場 / 非上場 で 0 or 1 で値を入れる
- 複雑な値でも論理積 (AND) を取れば良いので速い
- ORも早い
- 値の種類が少ないときに有効
ハッシュインデックス
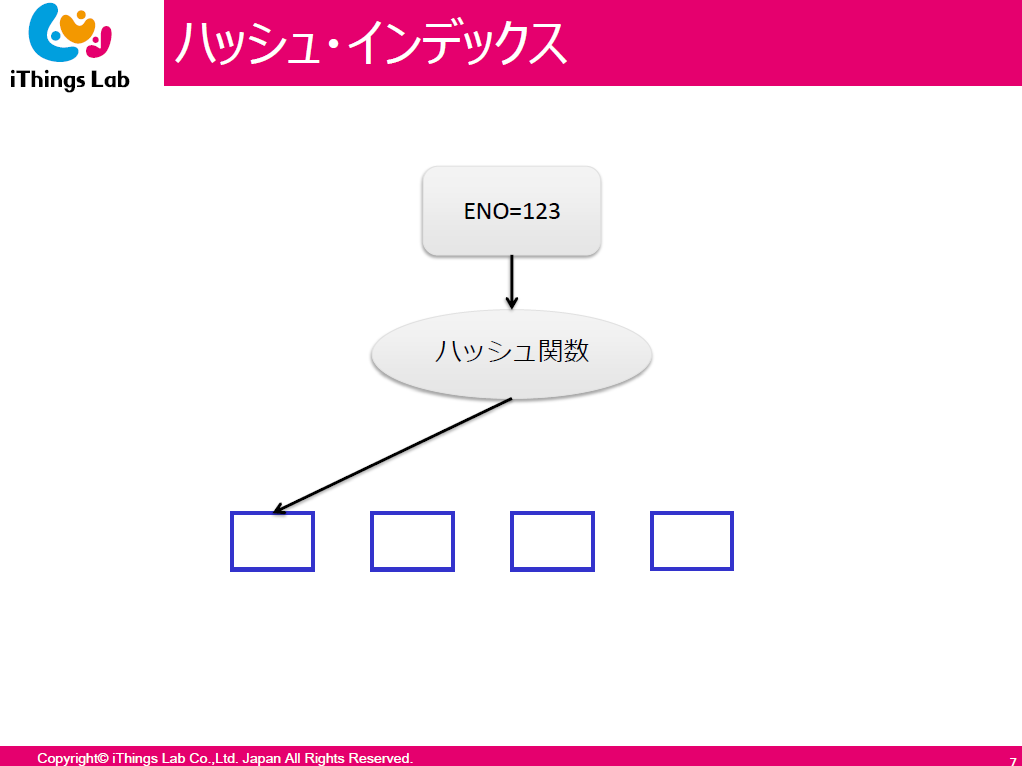
- ハッシュは均等分配する箱とイメージすると良い
- 3で割って 0 余る
- 3で割って 1 余る
- 3で割って 2 余る
WHERE ID=10だと 1 余る箱を探せば良い
逆キー
- 1013 1014 1015 1016 とインクリメンタルに値が格納されているテーブル
- これを 3101 4101 5101 6101 と逆にして
INSERTの待ちを発生させない
ナント。すごい発想です。。
演習する
ここからは実際にどういう検索ならインデックスが使われるのか、実際SQLを実行して試してみます。
準備
- カラム構成
- インデックスを作成
なお set autot traceonly とすると実行計画しか出ないので実行しましょう
色々実験してみる
林さんからSQL文を紹介してもらい、予想してから、実際に実行してみます。
case1
インデックスが実行されました。
case2
演算子 <> だと索引が使われない
101じゃないものというと全件検索しないとわからない
case3
LIKE '%S'後方一致だと索引は使われない- 末尾s では全件検索しないとわからない
case4
IS_NULL は索引を使わないが、 IS NOT NULL だと索引を使うことがある
やってみると不思議なもので、どういう値の持ち方をしているとインデックスが効くのか、頭の理解と感覚が一致するようになってきます。
インデックス作成のポイント

- ユニークな値が多い
- ただし、テキスト検索は別
- 大きな表とは
- 基準が難しいので悩むよりつけましょう
- ただし、 人の問題 で、作成すると取りにくくなる (後述)
演習
Q. この2つのSQLを索引を付けて早くしたい。どうするとよいか?
問題のSQL
試行錯誤してみる
- 索引が使われない
WHERE last_nameだと前方一致になるけど、WHERE first_nameだと後方一致になる
- 複合索引を貼るときは値の種類が多い方を第一引数にしたほうがよい
- なので
WHERE first_nameを早くしたければ、索引を新しく作る
試行錯誤2
- とやっていくと、SQL毎にインデックスを作ってしまいがち。結果、バックアップに時間がかかる
- バックアップのときに、インデックス毎にテーブルを作ってしまうため、容量が増える
- でいっぱい作ったインデックスを削除しようとすると、すでに何らかで使われてしまっているため、そのSQLが遅くなってしまう
- なのでインデックスを一度作ってしまうと削除するのが難しくなってしまう
実際にインデックスが増えてしまうことを体験して、このコースは終了しました。
まとめ
あやふやなまま使ってしまうことの多いインデックスについて、色々なインデックスの種類を知った上で、実際にSQLで実験し、どんなときに使えるのか、体感しました。
頭では分かっているつもりでも、実際予想しながらやることで、あ、これはアカンやつ、というのがわかるようになりました。
一方で、 SQLアンチパターン でも「インデックスショットガン」とも呼ばれる、インデックスが増えてしまう問題をやってみて、これまた判断が難しいことも分かりました。なかなか銀の弾丸は無いものなんですね。
インデックス設計を学びながら、悩ましいところも含め体験できるので、深掘りしたい方はもちろん、テーブル設計にも携わる方にもオススメのコースです!!
label SE カレッジの無料見学、資料請求などお問い合わせはこちらから!!
label SEカレッジを詳しく知りたいという方はこちらから !!
SEプラスにしかないコンテンツや、研修サービスの運営情報を発信しています。